
ES是一款高度可伸缩的、分布式的、近实时搜索的开源全文搜索与分析引擎。
- 分布式:ES是一款分布式搜索与分析引擎,底层实现还是基于Lucene的,核心思想是在多台机器上启动多个es进程实例,组成一个es集群。
- 高伸缩性:集群规模,可按需伸缩。索引的副本分片数也可动态调整,对读性能进行伸缩。
- 高可用性:ES提供了选主机制与副本机制,即使部分节点停止服务,整个集群依然可以正常服务。
- 近实时性:数据写入时,定期Refresh Segment到os cache,并且Reopen Segment方式保证搜索可以在较短时间(比如默认1秒)内被搜索到。
- 全文检索、数据分析
- 一个分布式的实时文档存储,每个字段 可以被索引与搜索
- 一个分布式实时分析搜索引擎
- 能胜任上百个服务节点的扩展,并支持 PB 级别的结构化或者非结构化数据
- 类似于 SQL 的分组(GROUP BY),而指标则类似于
COUNT()、SUM()、MAX()等统计方法。
创始人
创始人是Shay Banon,2004年基于Lucene开发了Compass,2010年重写Compass,取名Elasticsearch。

名言:Search is something that any application should have.
这和我对愿景的想法是一致的,有时候大家出于某种纯粹的理想去做事情,可能就成了。
版本
Elasticsearch(ES)有多个版本,以下是一些主要版本及其发布时间:
1.Elasticsearch 1.0 - 2014年2月发布
- 这是Elasticsearch的一个早期比较重要的版本,初步建立了其分布式搜索和分析引擎的基本架构,具备了基本的索引、搜索和聚合功能。
2.Elasticsearch 2.0 - 2015年10月发布
- 在1.0版本基础上改进了性能,优化了索引和搜索的一些算法。
- 增强了对数据处理的能力,例如在数据的索引和查询方面有了更多的功能优化。
3.Elasticsearch 5.0 - 2016年10月发布
- 性能提升显著,在索引速度、查询性能方面有很大改进。
- 对内部数据结构进行了优化,如引入了新的文档存储格式,提高了磁盘空间的利用率并提升了读写性能。
- 开始加强安全方面的功能,逐步走向企业级应用的成熟化。
4.Elasticsearch 6.0 - 2017年11月发布
- 进一步提升性能,尤其是在大规模数据处理场景下的性能优化。
- 对索引生命周期管理(Index Lifecycle Management)进行了增强,方便用户更好地管理索引从创建到删除的整个过程。
5.Elasticsearch 7.0 - 2019年4月发布
- 性能改进的同时,在数据摄入(ingest)管道方面进行了优化,使得数据进入Elasticsearch之前的处理更加灵活高效。
- 增强了安全功能,包括默认开启安全配置等措施,以更好地满足企业安全需求。
6.Elasticsearch 8.0 - 2022年2月发布
- 继续在性能、可扩展性方面发展,并且在与Kibana等Elastic Stack组件的集成方面更加紧密。
- 更加注重云原生特性,以适应现代云计算环境下的部署和使用需求。
后续使用7.1版本进行练习
生态圈
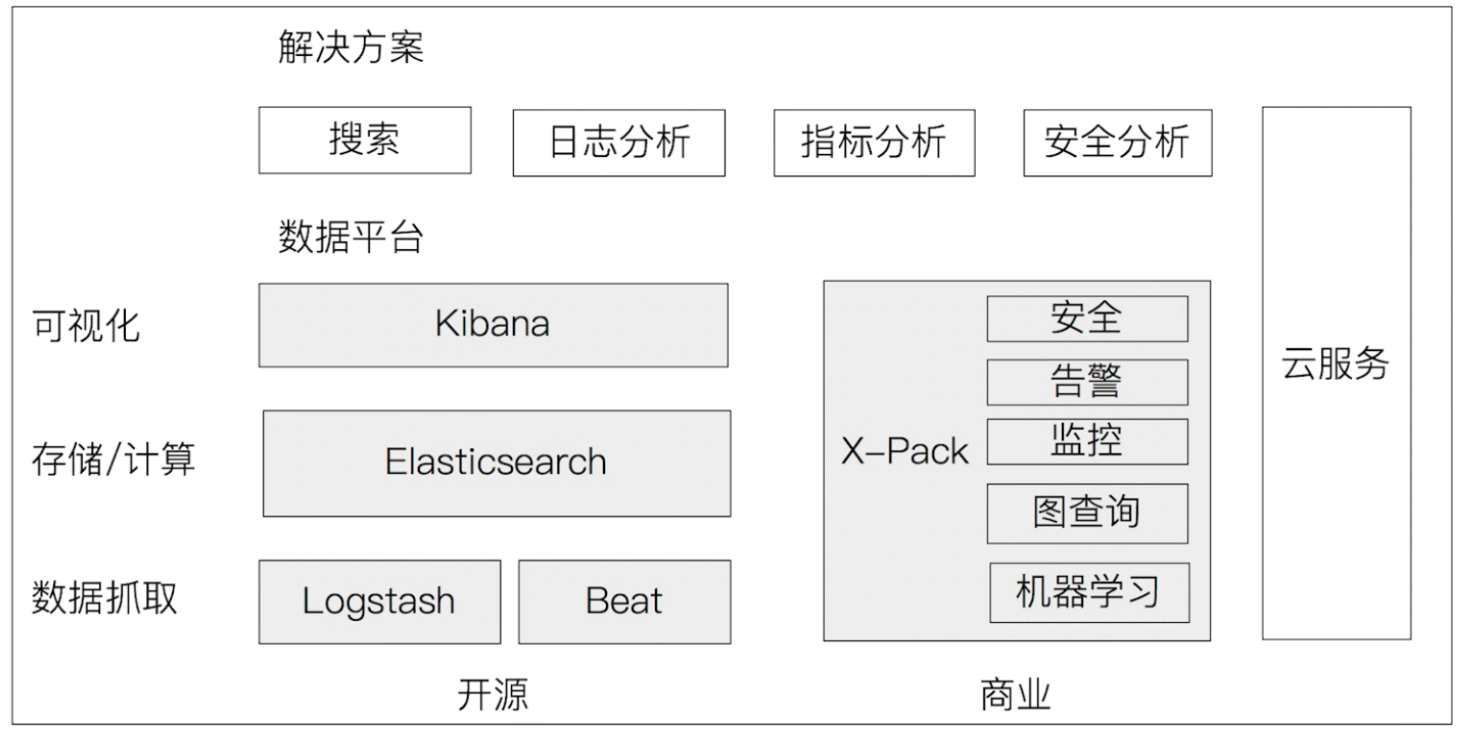
| 软件名称 | 作用 | 说明 |
|---|---|---|
| Kibana | 可视化分析利器,基于Logstash的数据可视化工具 | 2013被ES收购 |
| Elasticsearch | 数据存储、计算 | 核心 |
| Logstash | 数据处理管道,支持从不同来源采集数据,转换数据,并将数据发送到不同的存储库中。能实时解析和转换数据、可扩展200多插件、可靠性和安全性高、有监控 | 诞生于2009年,2013被ES收购 |
| Beat | 轻量的数据采集器,Go开发 | |
| X-Pack | 开源商业包,有不同收费策略 | 2018年开源 |
| 云服务 | 云服务方案 |
一般可以这样配合使用
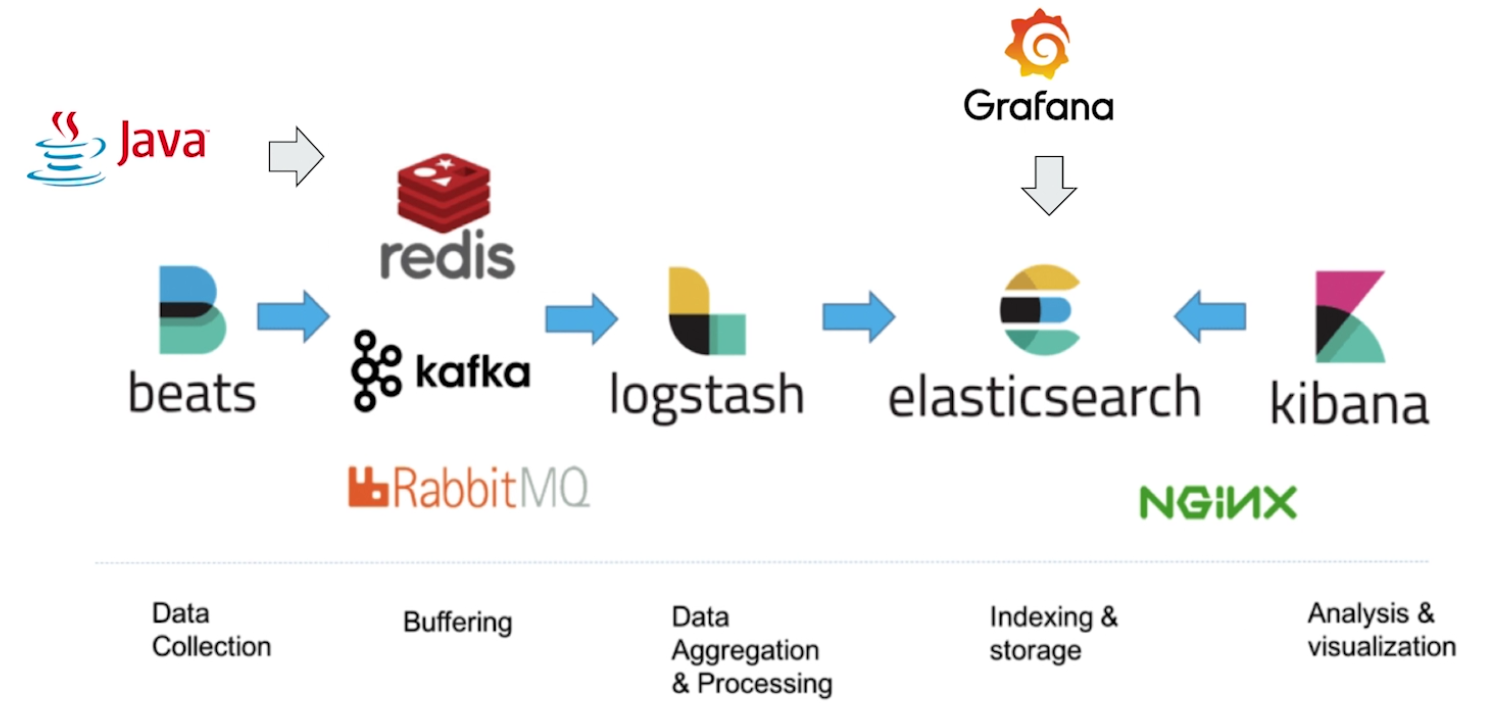
实操
下面我们安装一下生态圈的软件,并进行简单的使用。安装方式很多,可以选择Docker一键安装,这次我们用安装包在Mac上安装。可以中文官网进行下载。
Elasticsearch
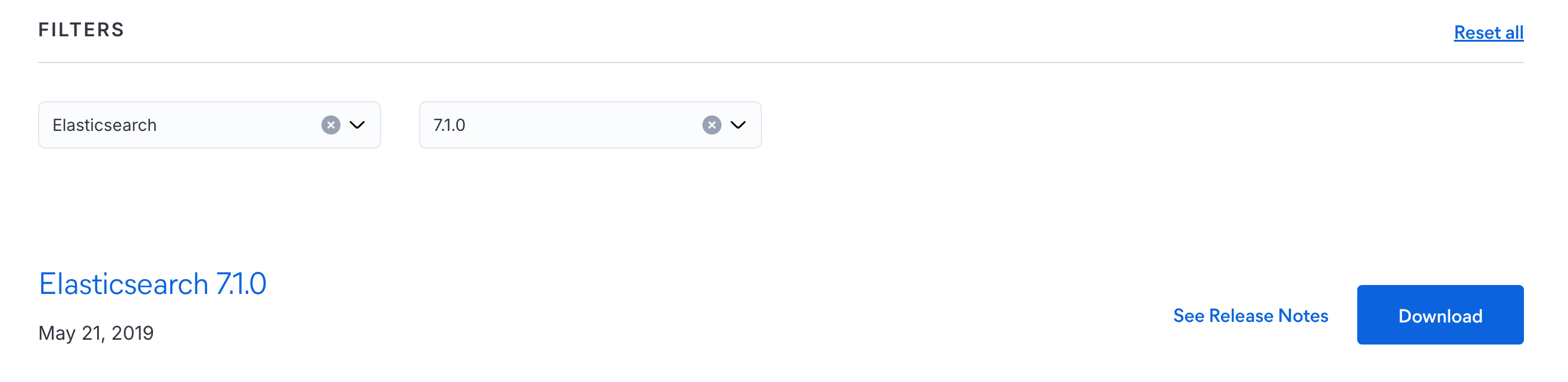
安装
下载地址:https://www.elastic.co/downloads/past-releases#elasticsearch ,我使用的7.1.0
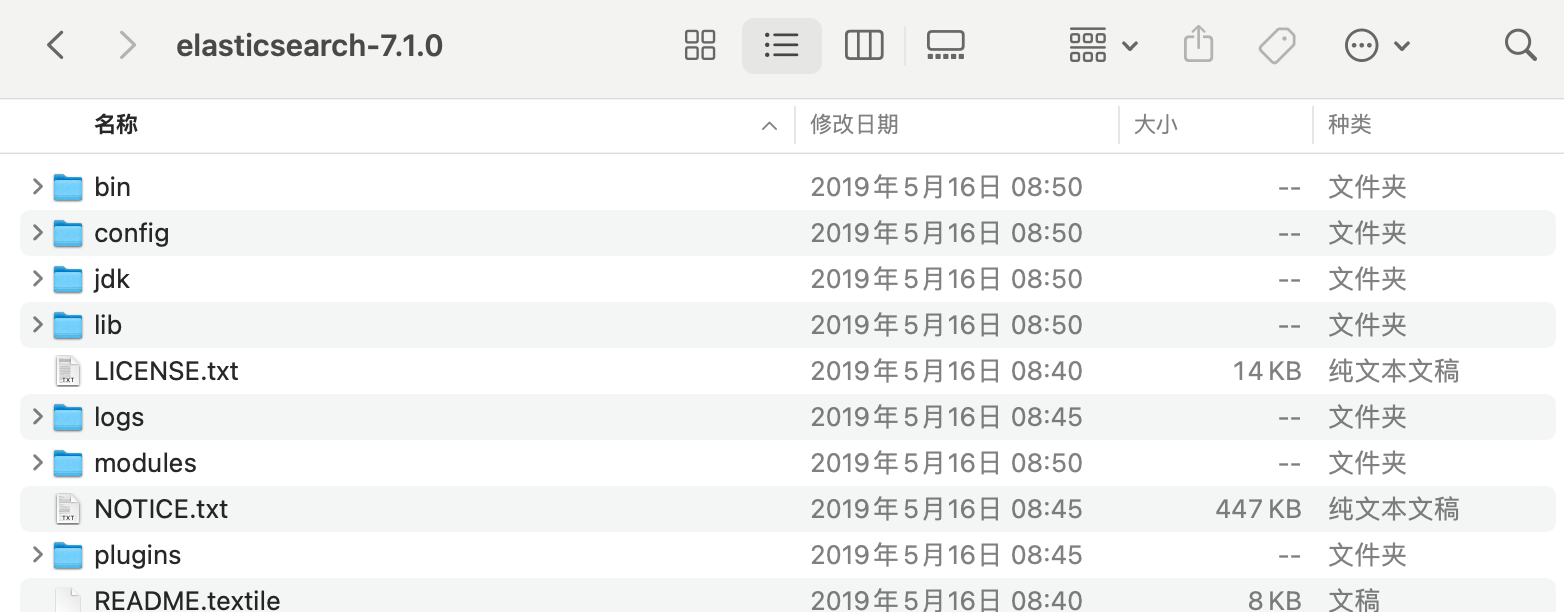
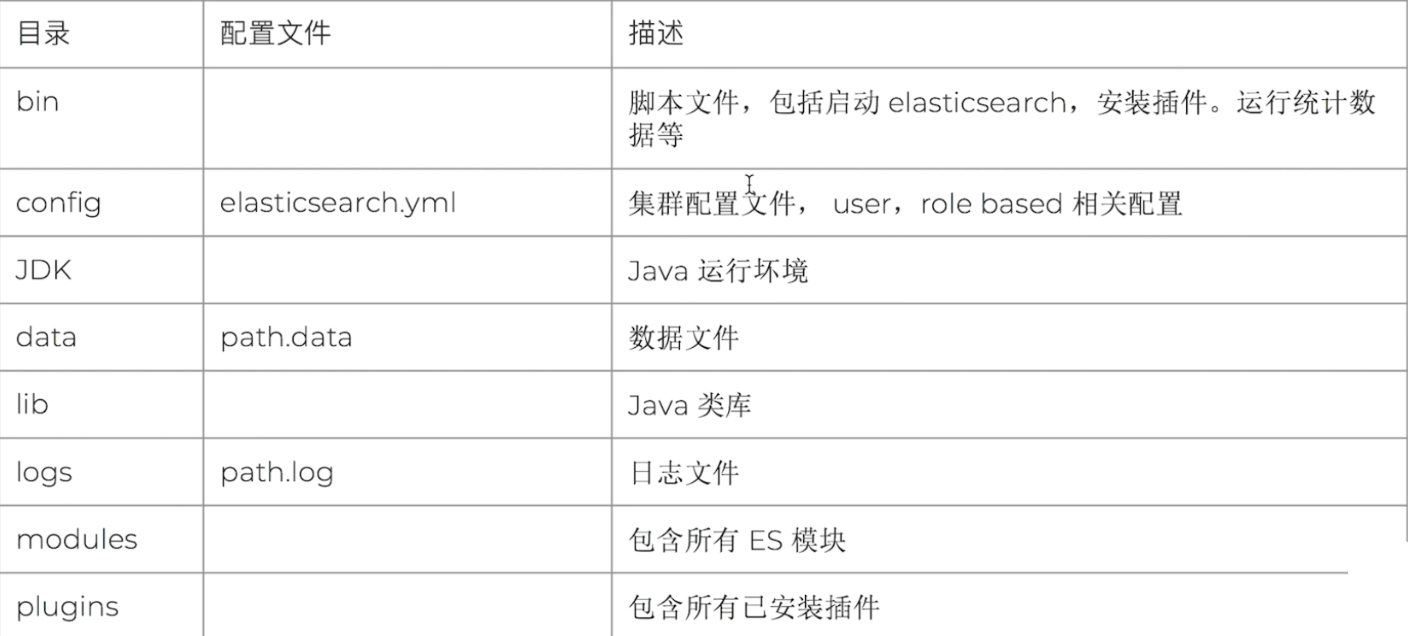
目录说明
解压完后可以看到目录如下:
常用命令
1 | 页面查看启动情况 http://localhost:9200/ |
配置完毕后,只能通过localhost访问,不能使用IP,如果想用IP,需要改config/elasticsearch.yml

Kibana
Kibana大家应该都会用到,一般查日志用的比较多。
安装
Elasticsearch是核心,所以Kibana版本需要和ES保持一致。
下载地址:https://www.elastic.co/downloads/past-releases#kibana
常用命令
1 | 页面查看启动情况:http://localhost:5601 |
安装成功后可以将一些数据导入ES,并在Kibana查看效果
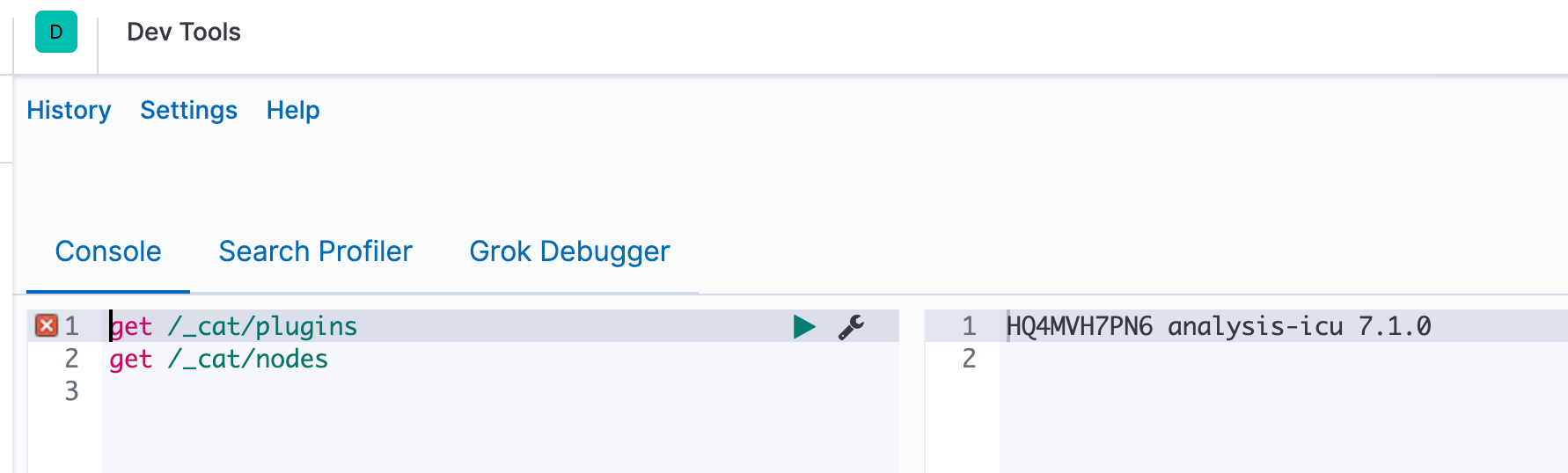
也可以使用Dev Tools功能,可以直接调试Es,目前看两者是无缝打通的
Cerebro
Cerebro不是Es的产品,是一个用于可视化和管理 Elasticsearch`集群的开源工具。它提供了一个直观的用户界面,让您能够轻松地监控、管理和诊断您的Elasticsearch集群。
安装失败
下载地址:https://github.com/lmenezes/cerebro/releases/tag/v0.8.3 ,下载tgz版本到本地,解压
安装jre:https://www.oracle.com/cn/java/technologies/downloads/archive/,选择11 https://www.oracle.com/cn/java/technologies/javase/jdk11-archive-downloads.html
docker安装
原生方式始终安装不成功,不浪费时间了,使用docker方式
1 | docker pull chanmufeng/cerebro:0.9.4 |
配置ES的地址(如果是docker启动的,使用ES IP的地址)
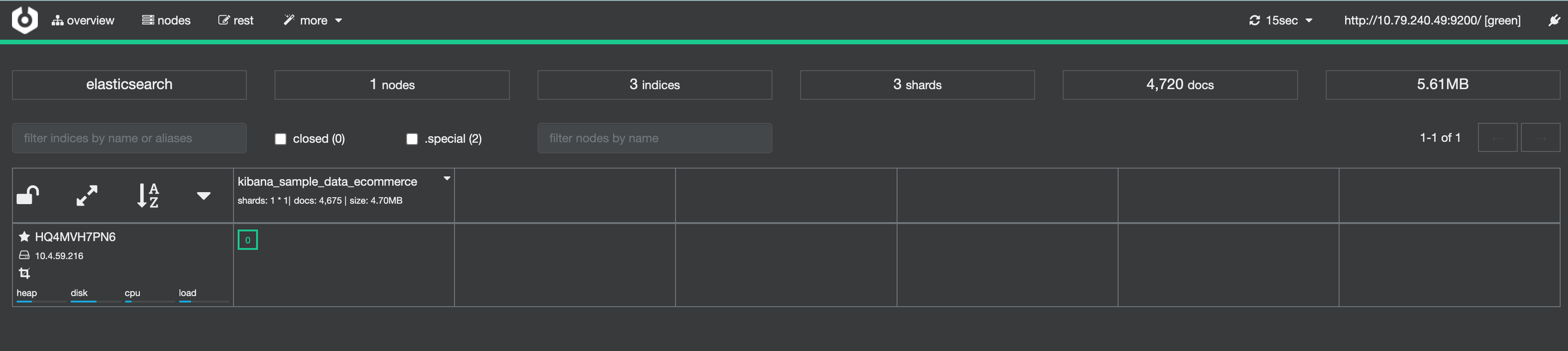
Logstash
安装
下载地址:https://www.elastic.co/downloads/past-releases#logstash
也需要和ES相同的版本,但在mac上各种报错,各种java相关的不兼容
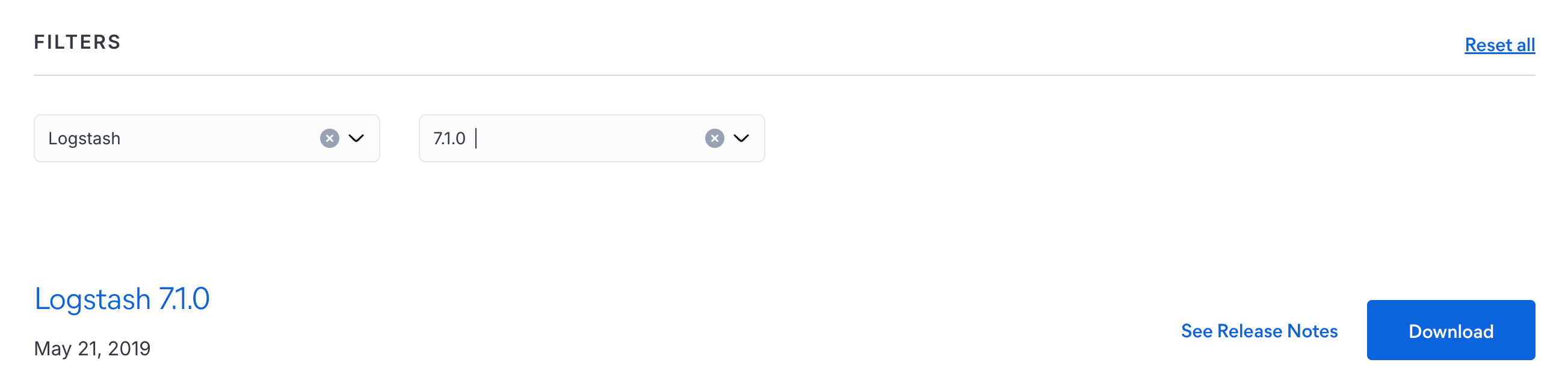
所以我选了7.10.0,这个有mac版,直接带JDK
操作
1 | 1. 启动:bin/logstash -f logstash.conf(自建的配置文件,要处理的数据源,如何处理) |
对应的logstash:logstash.conf
对应的数据文件: movies.csv
数据源:https://grouplens.org/datasets/movielens/
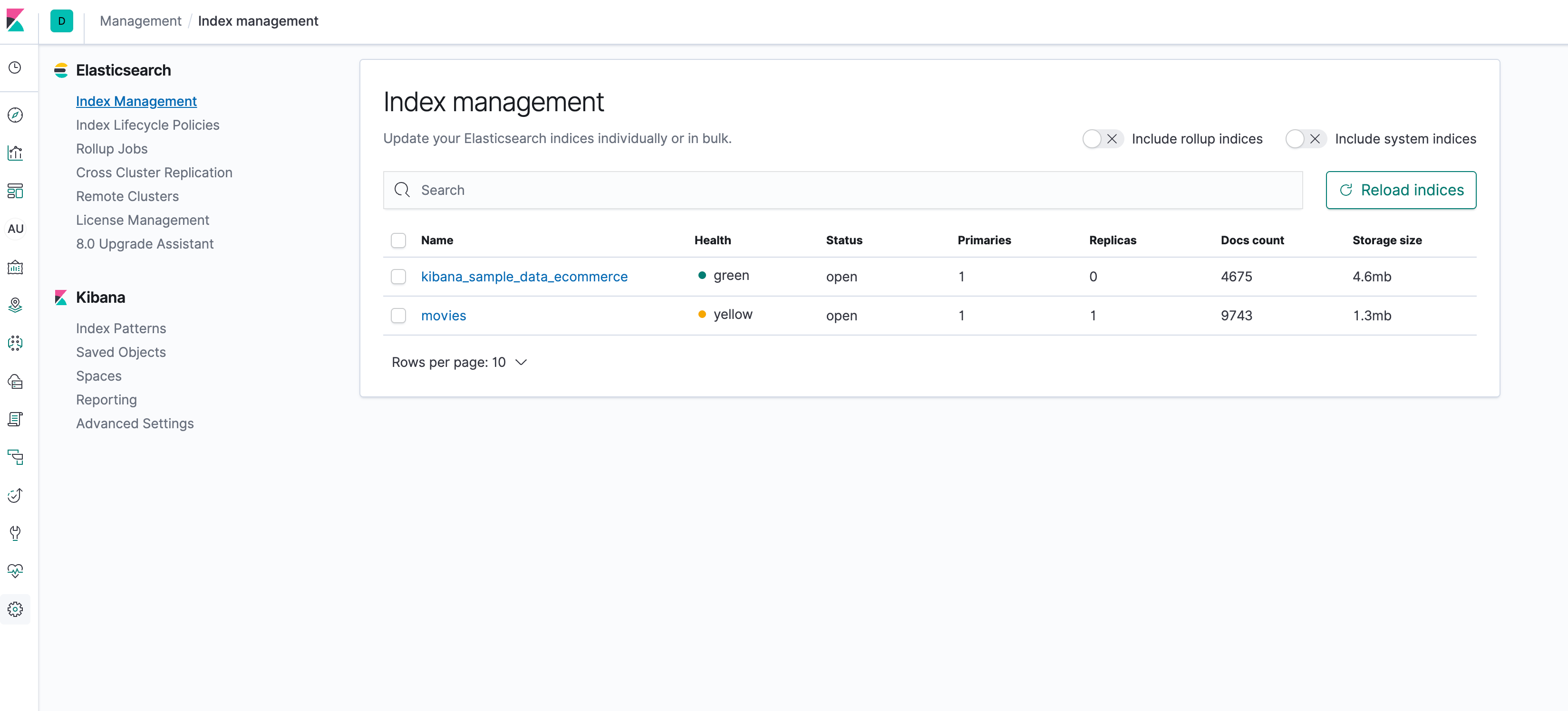
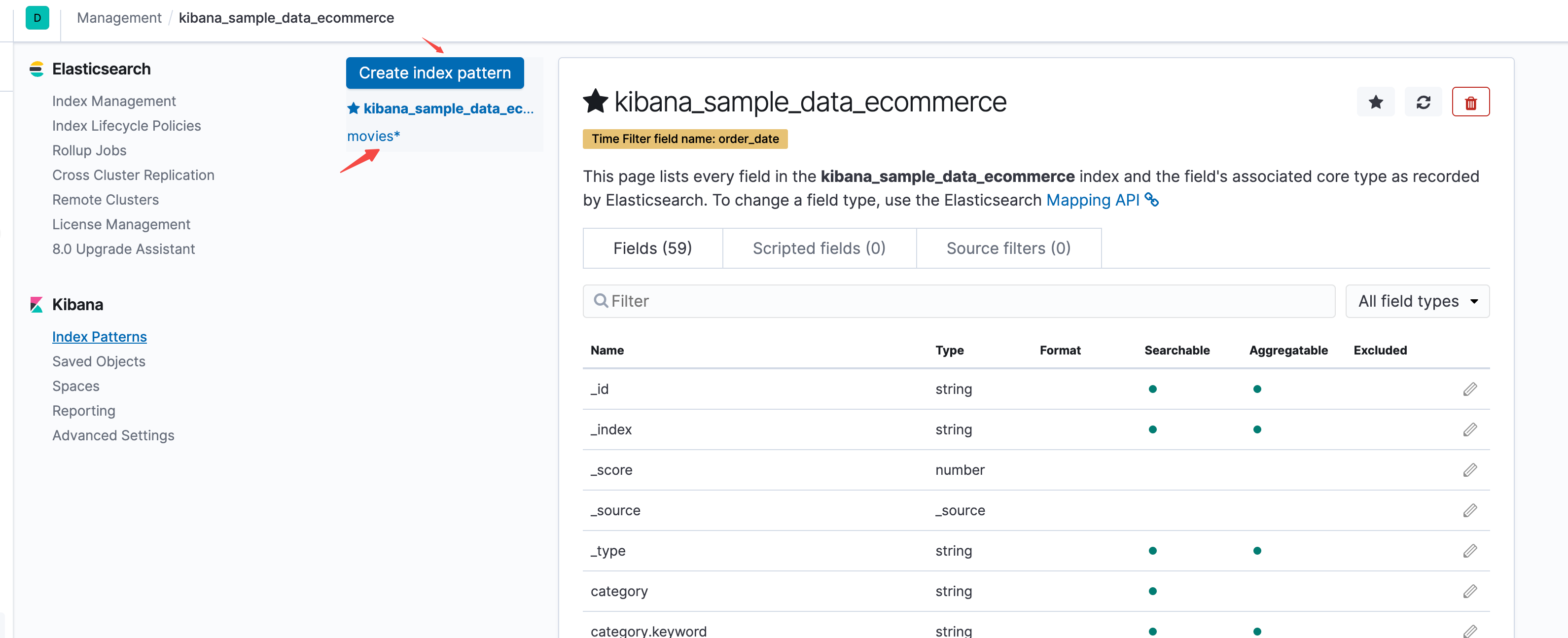
在Index Patterns创建索引
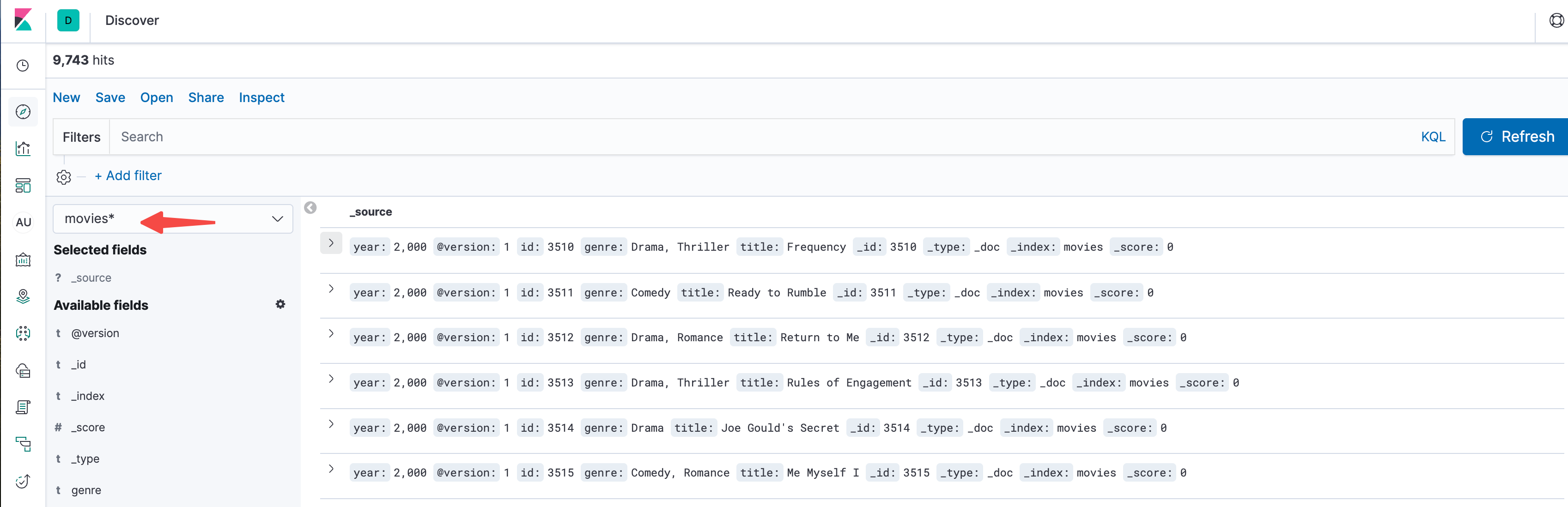
然后就能查看这些信息了
资料
- MacOS安装cerebro
- Elasticsearch 可视化集群工具 Cerebro
- macOS:卸载JRE或JDK
- db - Connection is not available
- M1芯片电脑安装cerebro
- 解决ElasticSearch本地只能通过localhost访问不能通过IP访问的问题。
- git资料
- [ERROR][org.logstash.Logstash ] java.lang.IllegalStateException: Logstas 报错解决
- Mac JDK环境变量配置 及 JDK多版本切换
- NotImplementedError: block device detection unsupported or native support failed to load
- Mac安装Ruby版本管理器(RVM)
- How to Install Ruby on macOS with RVM
- 如何在elasticsearch中查看Logstash打到elasticsearch的数据