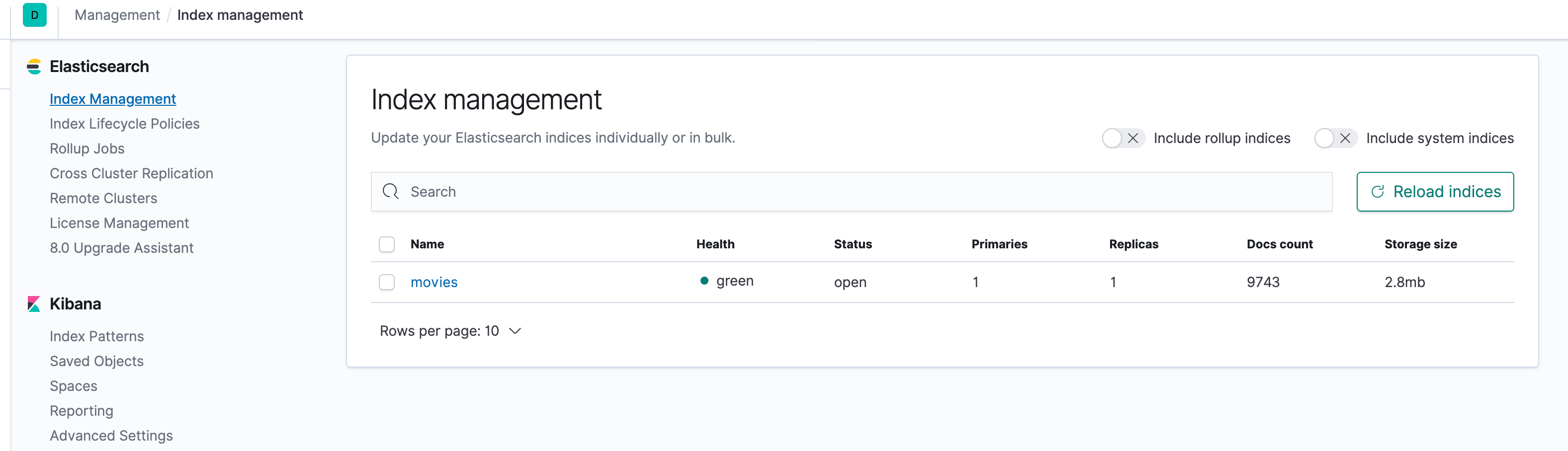
我们根据这张图过一下Elasticsearch上的各个概念。
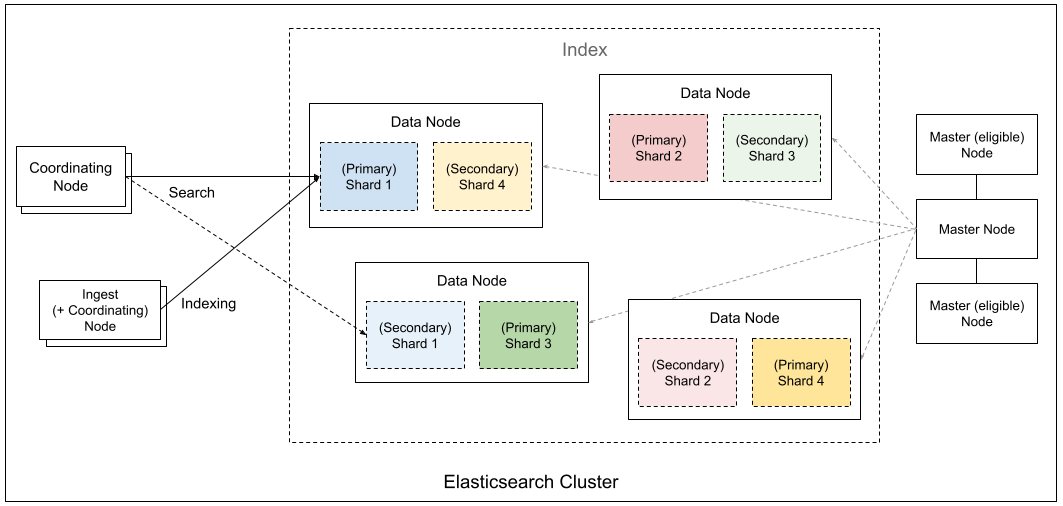
概念对比
ES有一些逻辑概念和物理概念,逻辑概念可以直接类比MySQL,能帮我们更好的使用ES开发业务。物理概念和Kafka等比较相似,能帮我们更好的运维。从逻辑概念上对比:
| 概念 | 类比MySQL |
|---|---|
| Elasticsearch | 关系型数据库(RDBMS),和MySQL同维度 |
| 集群(Cluster) | 库,如用户库,一个库里有多张表 |
| 索引(Index) | 表,如用户表 |
| 文档(Document) | 一行数据 |
| Filed | 对应表中的列 |
| Mapping | 对应表结构,Schema |
| 领域特定语言(DSL) | 对应SQL |
详细信息
我们按照图里结构,从大到小解释。
集群(Cluster)
- 不同的集群通过不同的名字来区分,默认名字“elasticsearch”
- 可以通过配置文件或者在命令行中 -E cluster.name=****进行设定
- 一个集群可以有多个节点
- 集群有状态
- red:某些数据不可用,注意此时仍然有部分功能是可用的
- yellow:所有数据均可用,但有一些副本尚未分配,即还不是处于高可用的状态
- green:运行正常
索引(Index)
说明
- 索引可以类比为MySQL的表,它包含逻辑空间的概念和物理空间的概念。
- 逻辑空间:对应Mapping,用于定义包含的文档的字段名和字段类型,类似于MySQL表结构
- 物理空间:对应Setting,用于定义数据存放在哪些分片上
- 一个集群内可以创建N个索引
实例
这是一个Document,是根据Elasticsearch家族成员及安装创建的。
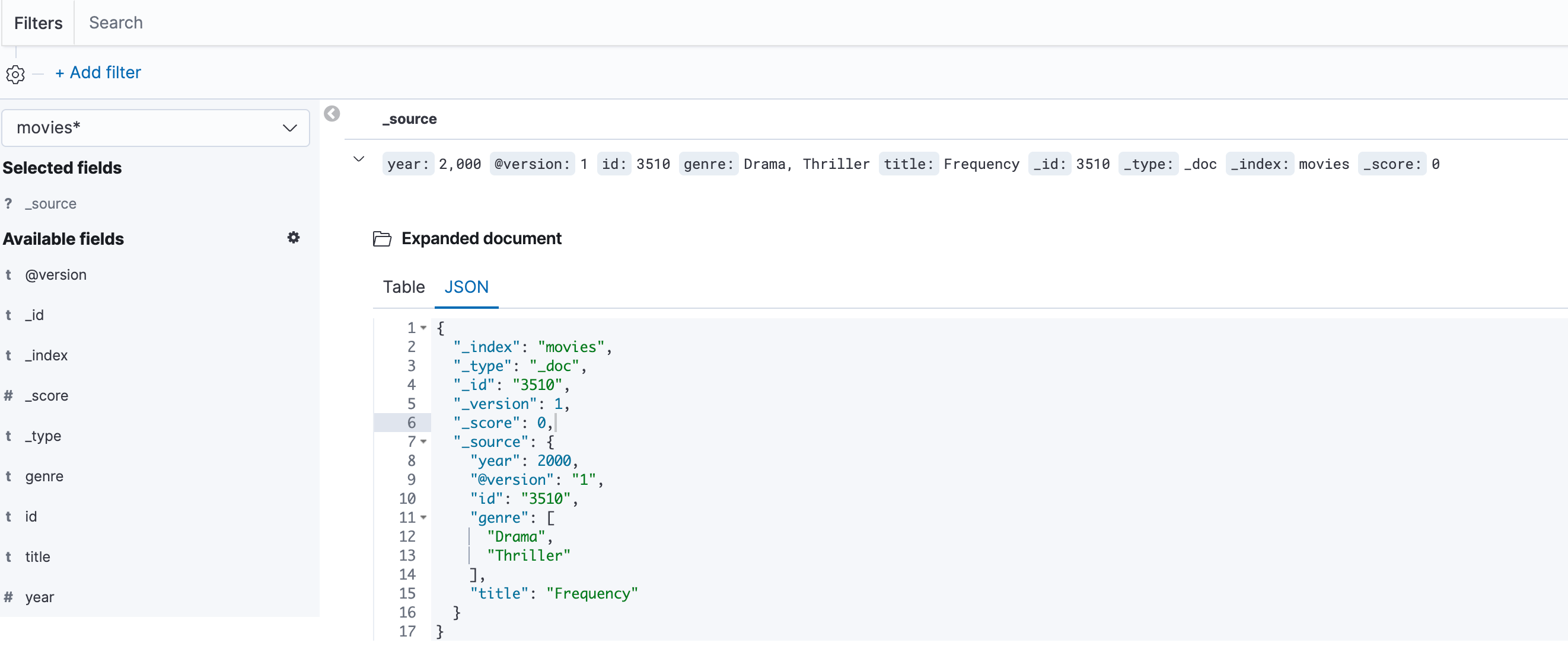
对应的索引Mapping和Setting为:
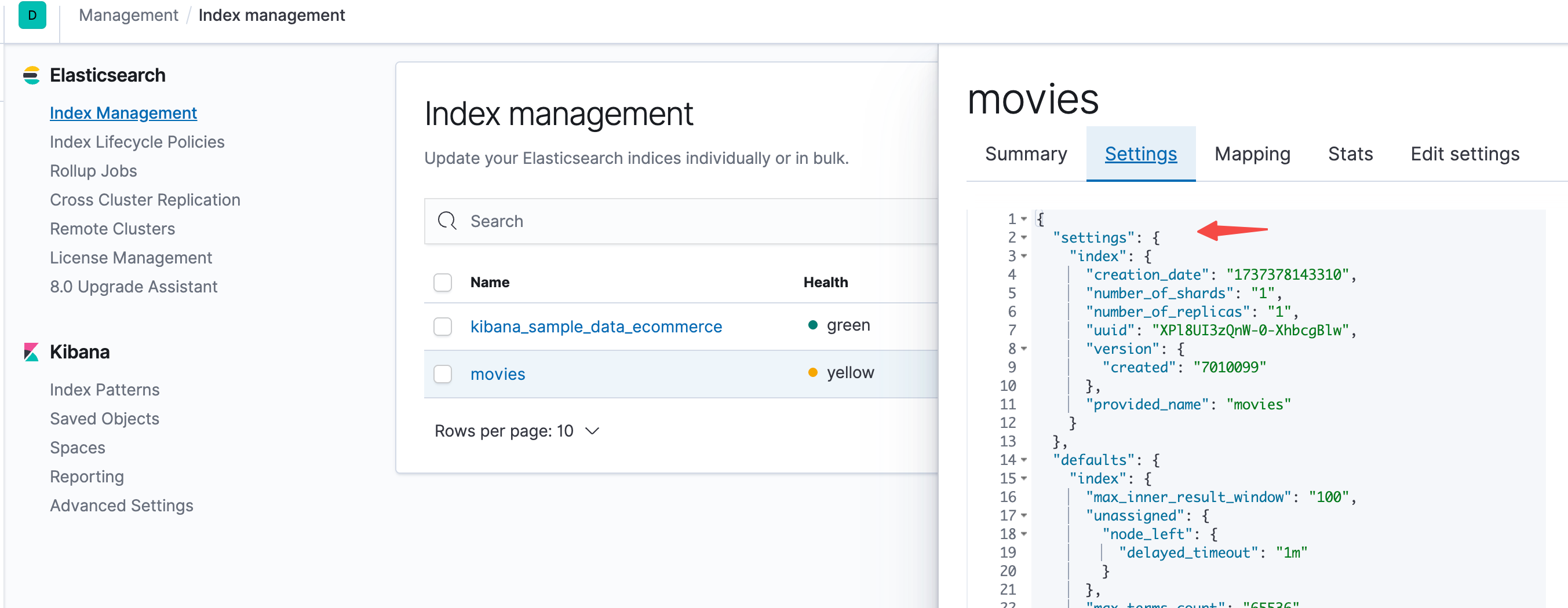
文档(Document)

- source:上一篇文章用logstash导入的原始数据
1 | movieId,title,genres |
- index:文档所属的索引名,可以自己指定,也可以通过Elasticsearch自动生成
- type:文档所属的类型名,7.0开始只能定义为_doc了
- id:文档的唯一id
- version:文档的版本信息,文档经过多少次改动
- score:相关性打分
所以Document是原始数据与基础性数据
节点(Node)
说明
- 节点是一个Elasticsearch的实例,本质上是一个JAVA进程。一台机器上可以运行多个进程,但生产环境一般建议一台机器值运行一个进程
- 每个节点都有名字,可以通过配置文件配置,或者启动时候 -E node.name=node1指定
- 每一个节点在启动之后,会分配一个UID,保存在data目录下
类型
| 节点名称 | 说明 |
|---|---|
| Master-eligible Node | 1. 节点启动默认是Master eligible节点,可通过设置node.master:false禁止 2. 该节点可以参加选主流程,成为Master节点 3. 保存了集群状态(所有节点信息,所有的索引和其Mappting/Setting信息,分片的路由信息) |
| Master Node | 从Master-eligible Node变成的,只有Master才能修改集群的状态信息 |
| Data Node | 保存数据的节点,负责保存分片的数据,在数据扩展上起到了至关重要的作用 |
| Coordinating Node | 1. 负责接受Client的请求,将请求分发到合适的节点,最终把结果汇集到一起,返回给Client 2. ES中的每一个节点,默认都起到Coordinating Node的职责 |
| Machine Learning Node | 负责跑机器学习Job,用来做异常检测 |
配置节点类型
ES启动的时候,通过读取elasticsearch.yaml控制node角色。一个节点可以承担多种角色。

分片(Shard)
主分片(Primary Shard)
因为要解决单机容量限制,所以采取集群方案,引入分片概念。通过主分片,可以将索引的数据分布到集群内的所有节点上,这个过程叫sharding。
- 一个分片是一个运行的Lucene实例
- 主分片数在索引创建时指定,后续不允许修改,除非Reindex
副本分片(Replica Shard)
用于解决高可用的方案,以防止数据丢失,为每个分片创建冗余,它允许你扩展吞吐量,因为在副本上也可以执行搜索。
- 副本分片数,可以动态调整
- 增加副本数,还可以提高服务可用性(读取的吞吐量)
分片数量
在索引的Setting中有两个字段
- number_of_shards:设置分片的数量,在集群中通常设置多个分片,表示一个索引库将拆分成多片分别存储不同的节点,提高了ES的处理能力和高可用性,7.x默认为1。
- number_of_replicas:设置副本的数量,设置副本是为了提高ES的高可靠性,默认为1。
分片数需要提前做好容量规划,避免过小或者过大。
- 分片数太小,如果后续数据太多,很难进行扩展。
- 分片数太大,如果超过Node数量,价值不大,而且太大了会影响搜索结果的相关性打分,影响统计结果的准确性
开发机配置多Nodes
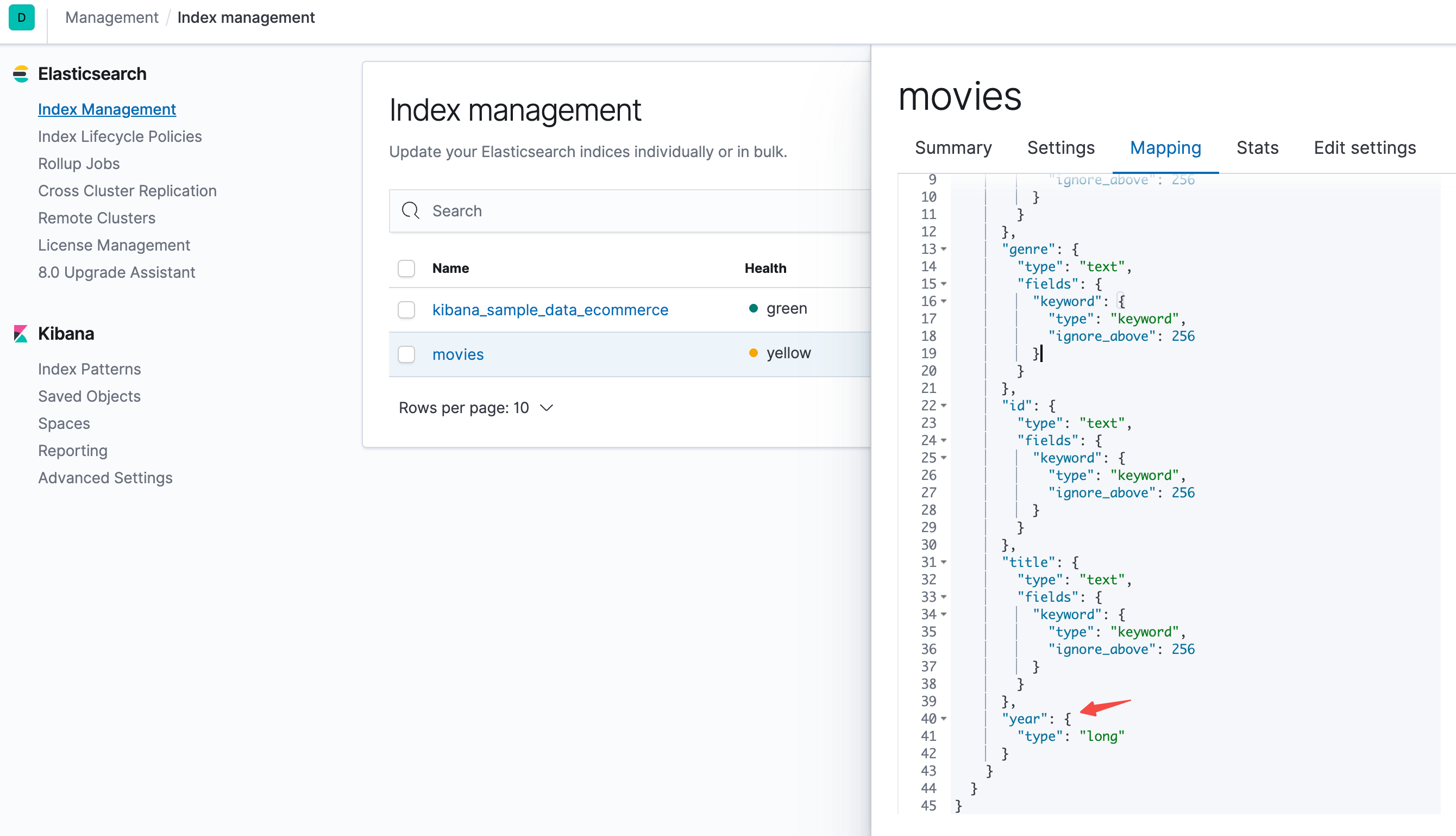
从Cerebro发现是yellow的
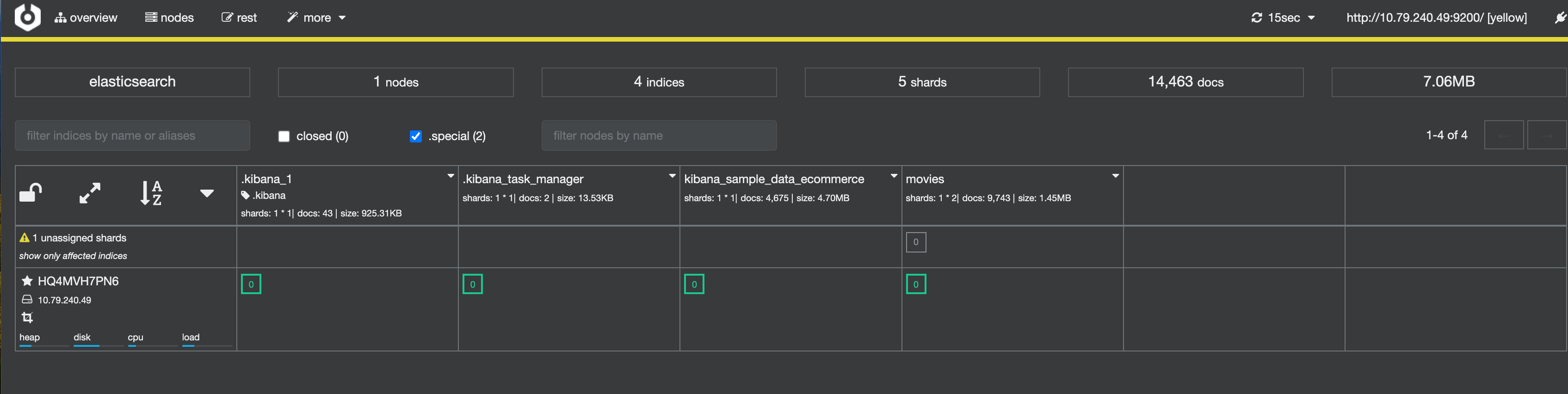
首先检查副本节点失败的原因
http://localhost:9200/_cat/shards?v&h=index,shard,prirep,state,unassigned.reason

我怀疑是因为主节点不会将主分片分配给与其副本相同的节点,也不会将同一分片的两个副本分配给同一个节点。我们增加一个试试,新建一个集群,有三个节点(配置文件需要改为初始情况)。
1 | bin/elasticsearch -E node.name=node1 -E cluster.name=geektime -E path.data=node1_data -d |
重新导入数据