
一、索引
ES中索引类似于MySQL的表,在MySQL中,我们使用Create创建表,在ES中我们使用什么方式?在2 Elasticsearch基本概念中说过mapping类比于MySQL对应的表结构-Schema。所以索引的创建使用的是Mapping。
1.1mapping介绍
Mapping类似数据库中的schema的定义,会把Json文档映射成Lucene所需要的扁平格式,作用如下
- 定义索引中的字段的名称
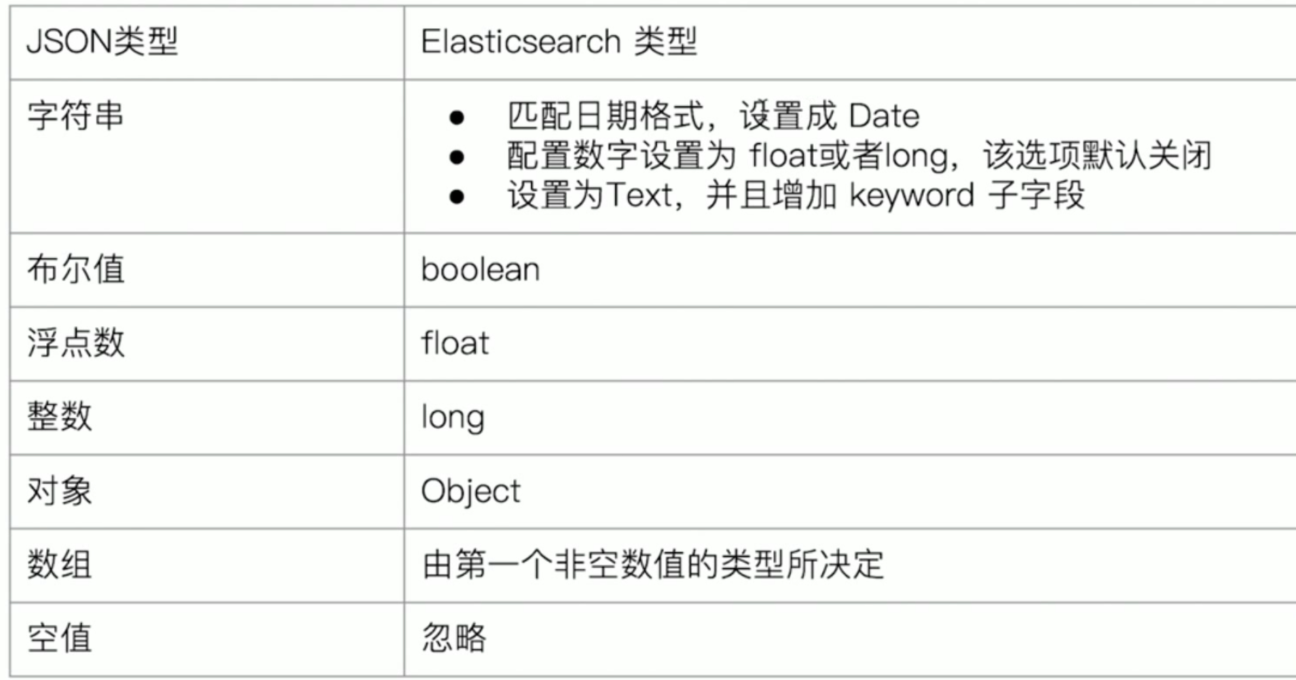
- 定义字段的数据类型,如字符串,数字,布尔等
- 字段倒排索引的相关配置,如Analyzed or Not Analyzed
1.2动态mapping
介绍
- 在写入文档时,如果索引不存在,会自动创建索引
- Dynamic Mapping机制,使得我们无需手动定义Mappings。Elasticsearch会自动根据文档信息,推算出字段的类型
- 但有时推算的不对,例如地理位置信息推算成text格式。
- 如果类型设置的不对,会导致一些功能无法正常运行,如Range查询
实战
创建索引
1 | PUT mapping_test/_doc/1 |
查看索引
1 | GET mapping_test/_mapping |
删除索引
1 | DELETE mapping_test |
修改索引
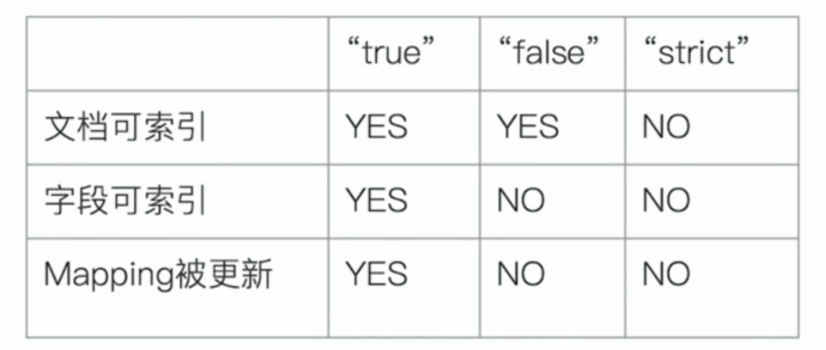
mapping中有个dynamic字段,有三个值,true(默认)、false、strict
- 为true时:一旦有新增字段的文档写入,mapping也同时被更新
- 为false时:mapping不会被更新,新增字段的数据无法被索引,但是信息会出现在_source中
- 为strict时:文档写入失败
对已有字段,一旦已经有数据写入,就不再支持修改字段定义,因为Lucene实现的倒排索引,一旦生成后,就不允许修改。如果希望修改字段类型,必须reindex api,重建索引
创建索引
1 | PUT dynamic_mapping_test/_doc/1 |
索引dynamic设置为false
1 | PUT dynamic_mapping_test/_mapping |
1 | { |
增加新字段
1 | PUT dynamic_mapping_test/_doc/10 |
1.3显式mapping
介绍
动态索引有时候不太准确,我们可以显示的进行配置。纯手写可能出现错误,所以我们可以准备一些样本数据,使用动态方案创建临时index,获取临时index,进行修改后创建真正的索引,最后把临时索引删除。
实战
1 | PUT users |
1.index字段控制是否被索引,默认为true,如果设置为false,该字段不可被搜索
2.Index_options:有四种不同级别的配置,控制倒排索引记录的内容。text类型默认postions,其它默认docs。记录内容越多,占用存储空间越大
- docs,记录doc id
- freqs,记录doc id和term frequencies
- positions,记录doc id、term frequencies、term position
- offsets,记录doc id、term frequencies、term position、character offects
3.copy_to:满足一些特定搜索需求,会将字段的数值拷贝到目标字段,用于搜索,但目标字段不出现在_source中
4.数组类型:ES不提供专门的数组类型,但是任何字段,都可以包含多个相同类型的数值
5.多字段类型:给同一个字段增加了多种搜索方式
- 如增加keyword字段,实现精确匹配
- 如使用不同的analyzer,更好的实现基于业务场景的搜索
- char_filter:在tokenizer之前对文本进行处理,例如增加删除及替换字符,可配置多个char_filter
- tokenizer:将原始的文本按照一定的规则,切分为词(term或token),有一些内置的tokenizers,如whitespace/standard/pattern等
- filter:将tokenizer输入的单词(term),进行增加、修改、删除,自带的如Lowercase/stop/synonym等
1 | GET _analyze |
如果索引中配置了某种analyzer,可以如此使用
1 | POST users/_analyze |
6.keyword和text的区别:keyword不需要分词,一般包括数字、日期或者具体的字符串
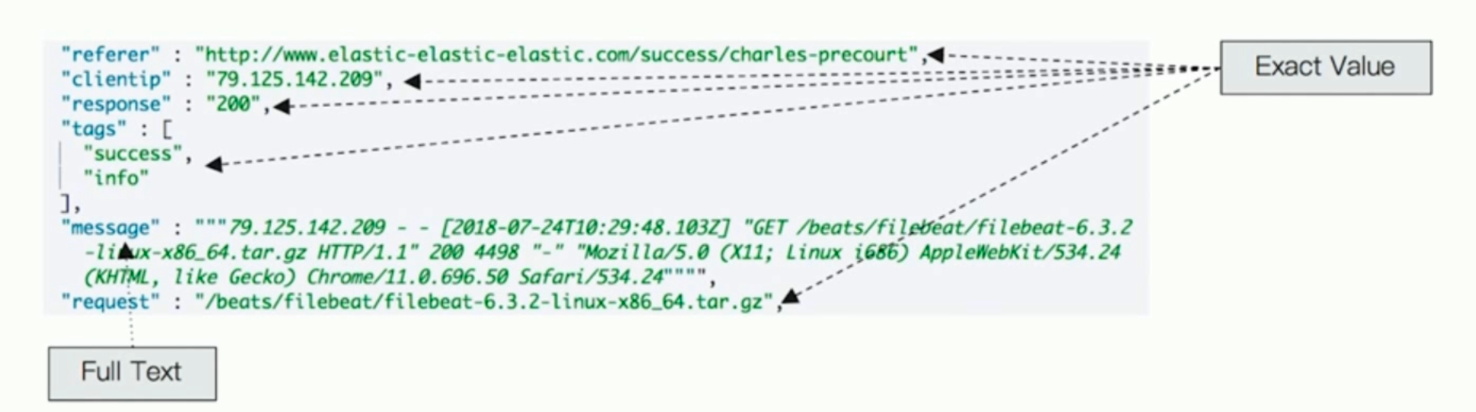
7.为了方便创建索引,我们还可以使用template
二、文档
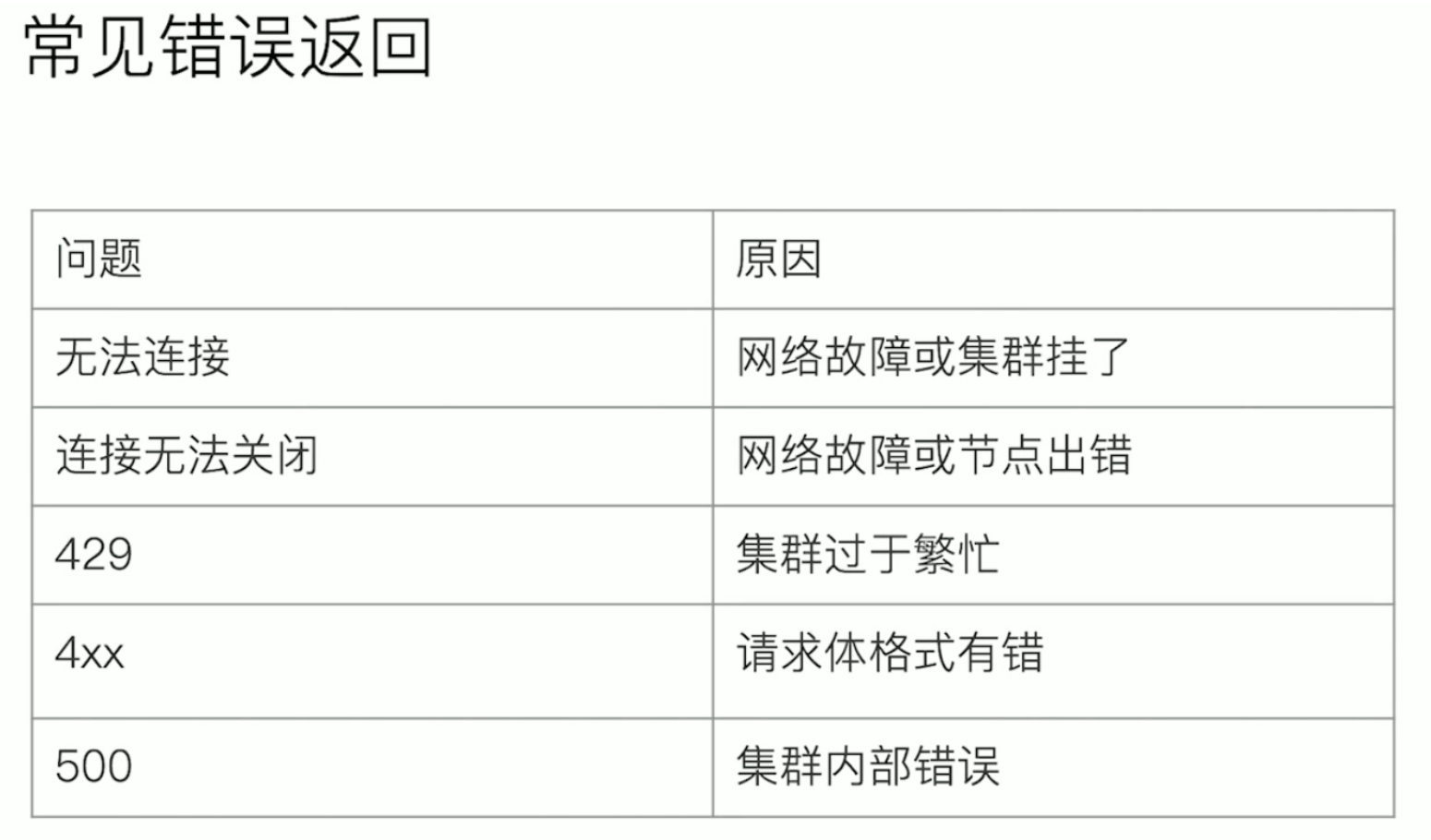
在执行操作的时候,有一些常见错误码
2.1创建文档
Index方式
- 如果Index不存在,会创建Index
- 如果ID不存在,创建新的文档,如果ID已存在,先删除现有文档,再创建新文档,版本增加
1 | POST users/_doc/1 |
Create方式
- 支持指定文档id和自动生成文档id两种方式
- 如果ID已存在,则创建失败
1 | PUT users/_create/3 |
2.2查询文档
1 | GET users/_doc/3 |
2.3更新文档
- update不会删除原来的文档,只会对相应字段做增量修改,版本增加
- 文档必须已经存在
- 可以增加新的字段
1 | POST users/_update/3/ |
2.4删除文档
1 | DELETE users/_doc/3/ |
2.5Bulk API
- 支持在一次API调用中,对不同的索引进行操作
- 支持四种类型Index、Create、Update、Delete,index、create、update后续要配置操作的数据
- 操作中单条操作失败,并不会影响其它操作
1 | POST _bulk |
2.6批量读取mget
- 能够减少网络连接所产生的开销,提高性能
1 | GET /_mget |
2.7批量查询msearch
1 | POST test2/_msearch |
三、搜索
3.1介绍
ES有两种搜索方式
- URI Search:在URL中使用查询参数
- Request Body Search:使用ES提供的,基于JSON格式的更加完备的Query Domain Specific Language(DSL)。这种方式更加高级,一般建议使用这种方式。
3.2 Query String Syntax(查询语法)
指定字段 vs 泛查询
q=title:2012 -> 查询title字段包含2012的
q=2012 -> 查询所有字段中包含2012的
Term Query vs Phrase Query
- Beautiful Mind:等效于Beautiful OR Mind,查询字段中包含Beautiful或者Mind的
- ”Beautiful Mind“:等效于Beautiful AND Mind,查询字段中同时包含Beautiful和Mind,要求前后顺序保持一致
分组
- title:(Beautiful Mind) -> 表明Beautiful和Mind是一块的,有点类似于数学表达式中的括号,用于明确操作的优先级。
- title:(+Beautiful -Mind) -> +标识must,-标识must_not
布尔操作
- AND/OR/NOT 或者 &&/ || /!,必须大写
- title:(Beautiful NOT Mind) -> 查询包含Beautiful不包含Mind的
范围查询
区间查询:[]闭区间,{}开区间
year:{2018 TO 2019]
year:[* TO 2018]
算数符号
- year:>2010
- year:(>2010 AND <=2018) 查询大于2010年,小于等于2018年的电影
通配符查询
通配符查询效率低,占用内存大,不建议使用。?代表一个字符,*代表0或者多个字符
- title:mi?d
- title:be*
模糊匹配与近似查询
在使用term查询或者match查询时,如果在查询的字符串后面加上~,可以实现近似匹配。这种模糊查询在处理拼写错误、用户输入可能存在小偏差等场景下非常有用,它可以扩大搜索结果的范围,提高搜索的召回率,使得即使输入的查询词不完全准确,也能找到相关的文档。
- title:beautifl~1
- title:”lord rings”~2
3.3实战
3.3.1查询指定的索引
集群上所有的索引
1 | GET _search |
指定索引
1 | GET movies/_search |
指定多个索引
1 | GET test,test2/_search |
指定开头的索引
1 | GET test*/_search |
3.3.2URI搜索
URI的样式如下,大家可以按照查询语法中的方式随意进行更改
- 使用q指定查询字符串,使用query string syntax
- df默认字段,不指定时,会对所有字段进行查询
- df和q是配合使用的,如果有df,则意味df的字段值为q
- 可以不使用df,q中直接写明字段和要查询的值
- sort排序方式
- from,size用于分页
- profile查看查询是如何被执行的
1 | GET /movies/_search?q=2012&df=title&sort=year:desc&from=0&size=10&timeout=1s |
3.3.3Request Body搜索
特殊配置
- 分页:从0开始,默认返回10个结果。获取靠后的翻页成本较高,因为在 Elasticsearch 中,当进行分页查询时,例如查询第
n页(n较大,即靠后的页面),默认情况下,Elasticsearch 需要从所有匹配的文档中获取到前面n - 1页的文档后,才能得到第n页的文档。 - 排序:最好在数字型或者日期型字段上排序。因为对于多值类型或分析过的字段排序,系统会选一个值,无法得知该值
- sorce filtering:返回指定的字段,支持通配符
- 使用脚本对字段进行处理:
1 | POST /movies/_search |
查询表达式Match
搜索title包含last或者christmas
1 | POST movies/_search |
搜索title同时包含last和christmas
1 | POST movies/_search |
短语搜索Match Phrase
在 ES 查询中,match和match_phrase的区别在于:
match:会将查询字符串进行分词,然后在索引中查找与分词后的词项匹配的文档。它会根据查询字段的类型自动调整查询方式,例如对于日期或数值类型的字段,会将查询字符串转换为相应的日期或数值进行比较。match查询在处理可分词的文本字段时非常有用,可以根据用户输入的关键词进行模糊匹配,找到包含相关词项的文档。match_phrase:要求查询字符串中的短语按照顺序完整匹配字段内容。它不会对查询字符串进行分词,而是将整个查询字符串作为一个短语进行匹配。match_phrase查询在需要精确匹配短语或按照特定顺序匹配关键词时非常有用。
查询title包含one love,中间可以有一个词的间隔
1 | POST movies/_search |
Query String
类似于URI搜索
- default_field是df,指定要搜索的字段
- fields指查询的多个字段
1 | POST movies/_search |
Simple Query String Query
- 类似Query String,但会忽略错误的语法,同时只支持部分查询语法
- 不支持AND OR NOT,会当做字符串处理
- Term之间默认的关系是OR,可以指定Operator
- 支持部分逻辑,+替代AND,|替代OR,-替代NOT
1 | POST movies/_search |