
这章我们看一下Elasticsearch搜索相关内容。
一、查询过程
理解查询过程,有助于我们理解搜索相关的API。
1.1GET
例如,我们查询一个指定_id的文档,查询users索引下,_id=3的文档
1 | GET users/_doc/3 |
收到请求,先获取集群的状态信息
根据路由信息计算id是在哪一个分片上
因为一个分片可能有多个副本分片,所以上述的计算结果是一个列表
调用transportServer的sendRequest方法向目标发送请求
上一步的方法内部会检查是否为本地node,如果是的话就不会发送到网络,否则会异步发送
等待数据节点回复,如果成功则返回数据给客户端,否则会重试
重试会发送上述列表的下一个。
1.2SEARCH
search有两大类搜索类型
- dfs_query_then_fetch/dfs_query_and_fetch,流程复杂一些,但是算分的时候使用了全局的一些指标,这样获取的结果可能更加精确一些。
- query_then_fetch/query_and_fetch,默认的搜索类型。
Then:第一阶段查询到匹配的docID,第二阶段再查询DocID对应的完整文档。这种在ElasticSearch中称为query_then_fetch,原因是需要多个分片聚合汇总,如果数据量太大那么会影响网络传输效率,所以第一阶段会先返回id。
And:一阶段查询的时候就返回完整Doc,在ElasticSearch中叫query_and_fetch,一般适用于只需要查询一个Shard的请求。因为这种一次请求就能将数据请求到,减少交互次数。
核心查询阶段包含以下四个步骤:
- 客户端发送一个 search 请求到 NodeA , NodeA 会创建一个大小为 from + size 的空优先队列。
- NodeA 将查询请求转发到索引的每个主分片或副本分片中。每个分片在本地执行查询并添加结果到大小为 from + size 的本地有序优先队列中。
- 每个分片返回各自优先队列中所有文档的 ID 和排序值给协调节点,也就是 NodeA,它合并这些值到自己的优先队列中来产生一个全局排序后的结果列表。
- 当一个搜索请求被发送到某个节点时,这个节点就变成了协调节点。这个节点的任务是广播查询请求到所有相关分片并将它们的响应整合成全局排序后的结果集合,这个结果集合会返回给客户端。
二、Search API
官方文档上的API:https://www.elastic.co/guide/en/elasticsearch/reference/7.1/query-filter-context.html 。我们找一些比较重要的。
在Search中有两个概念,Query(过滤器上下文) 和 filter context(过滤器上下文)
相关性得分:默认情况下,Elasticsearch 按相关性得分对匹配的搜索结果进行排序,该得分衡量每个文档与查询的匹配程度。相关性得分是一个正浮点数,在搜索 API 的 _score 元字段中返回。_score 越高,文档越相关。虽然每种查询类型可以以不同方式计算相关性得分,但得分计算也取决于查询子句是在查询上下文还是过滤器上下文中运行。
查询上下文:在查询上下文中,查询子句回答 “此文档与该查询子句的匹配程度如何?” 除了决定文档是否匹配之外,查询子句还在 _score 元字段中计算相关性得分。只要将查询子句传递给查询参数(例如搜索 API 中的查询参数),就会处于查询上下文。
过滤器上下文:在过滤器上下文中,查询子句回答 “此文档是否与该查询子句匹配?” 答案是简单的是或否 - 不计算得分。过滤器上下文主要用于过滤结构化数据,例如:
此时间戳是否在 2015 年到 2016 年范围内?
状态字段是否设置为 “已发布”?
Elasticsearch 会自动缓存经常使用的过滤器,以提高性能。只要将查询子句传递给过滤器参数(例如布尔查询中的过滤器或 must_not 参数、constant_score 查询中的过滤器参数或过滤器聚合),就会处于过滤器上下文。
2.1Term-level queries术语查询
Term是表达语义的最小单位。搜索和利用统计语言模型进行自然语言处理都需要处理Term。
- 在ES中,Term查询,对输入不做分词,会将输入作为一个整体,在倒排索引中查找准确的词项,并且使用相关度算分公式为每个包含该词项的文档进行相关度算分
- 可以通过Constant Score将查询转换成一个Filtering,避免算分,并利用缓存,提高性能
- 避免使用term查询text
API列表
- exists query:返回包含某个字段的任何索引值的文档。
- fuzzy query:返回包含与搜索词相似的术语的文档。Elasticsearch 使用 Levenshtein 编辑距离来衡量相似性或模糊性。
- ids query:根据文档的 ID 返回文档。
- prefix query:返回在提供的字段中包含特定前缀的文档。
- range query:返回包含在提供范围内的术语的文档。
- regexp query:返回包含与正则表达式匹配的术语的文档。
- term query:返回在提供的字段中包含确切术语的文档。
- terms query:返回在提供的字段中包含一个或多个确切术语的文档。
- terms_set query:返回在提供的字段中包含至少一定数量确切术语的文档。你可以使用字段或脚本定义匹配术语的最小数量。
- type query:返回指定类型的文档。
- wildcard query:返回包含与通配符模式匹配的术语的文档。
term query API说明
1 | GET /_search |
实战
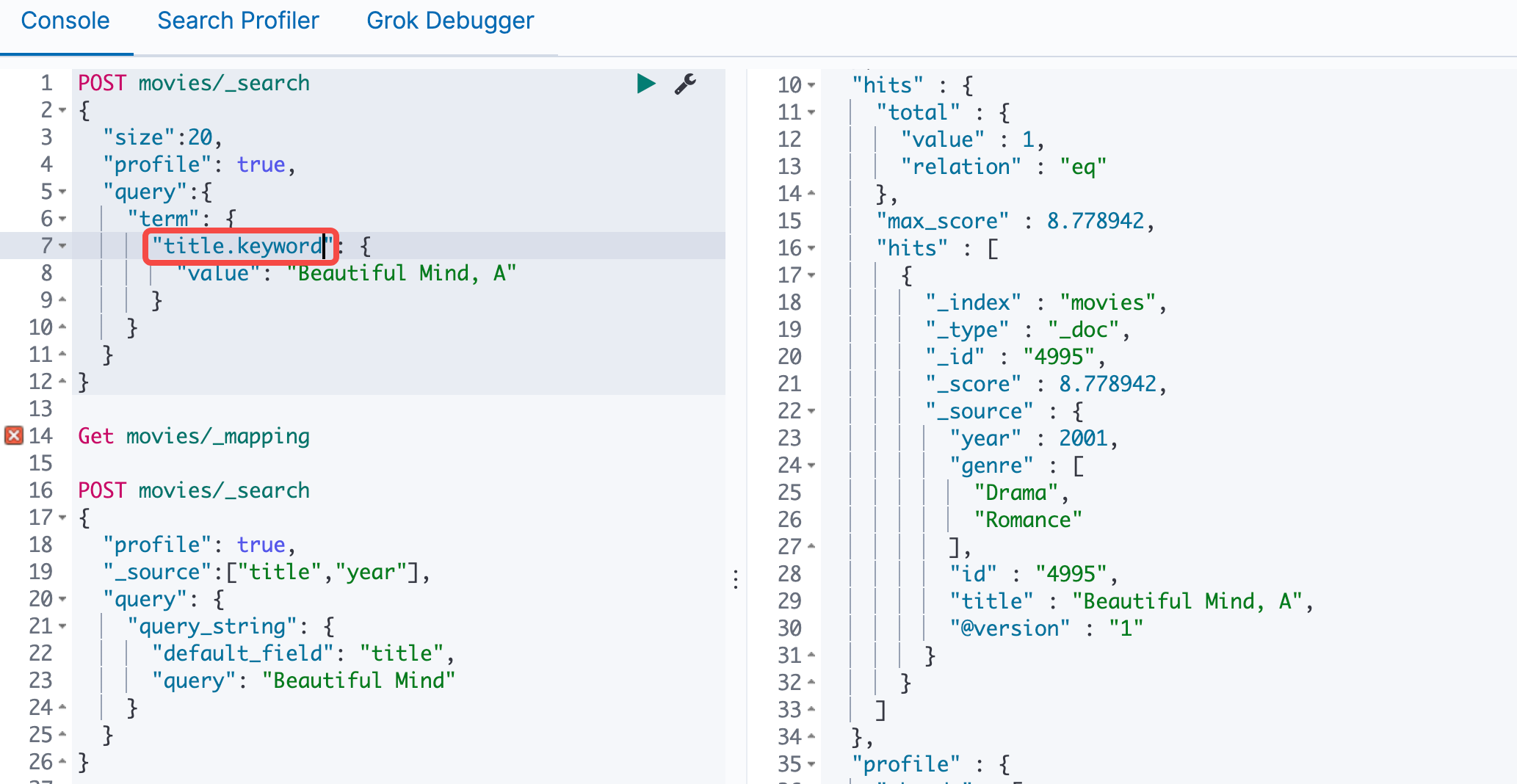
首先我们可以看到movies中有很多beautiful的电影
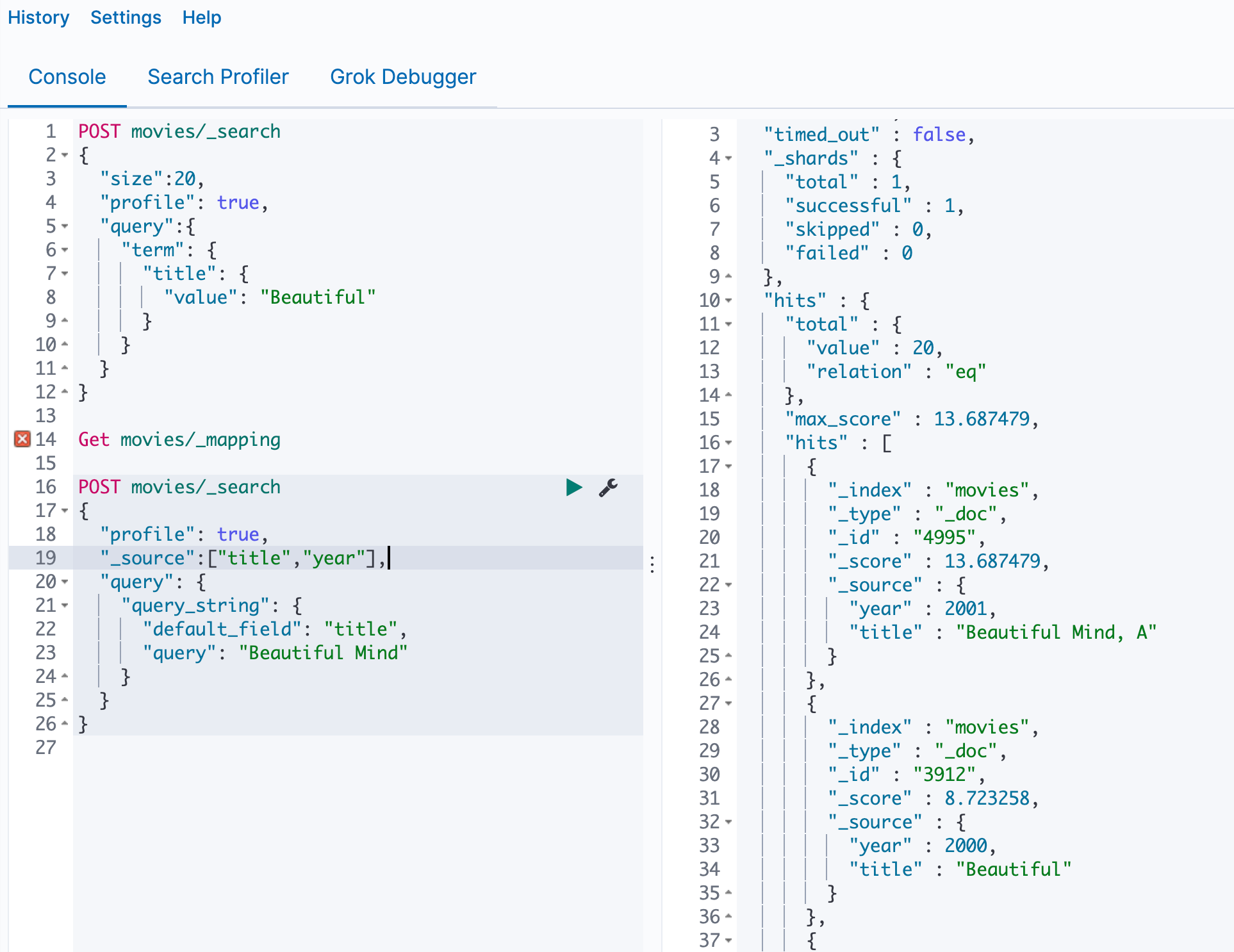
使用Term查询,发现数量为0,这是因为电影名都做了小写处理
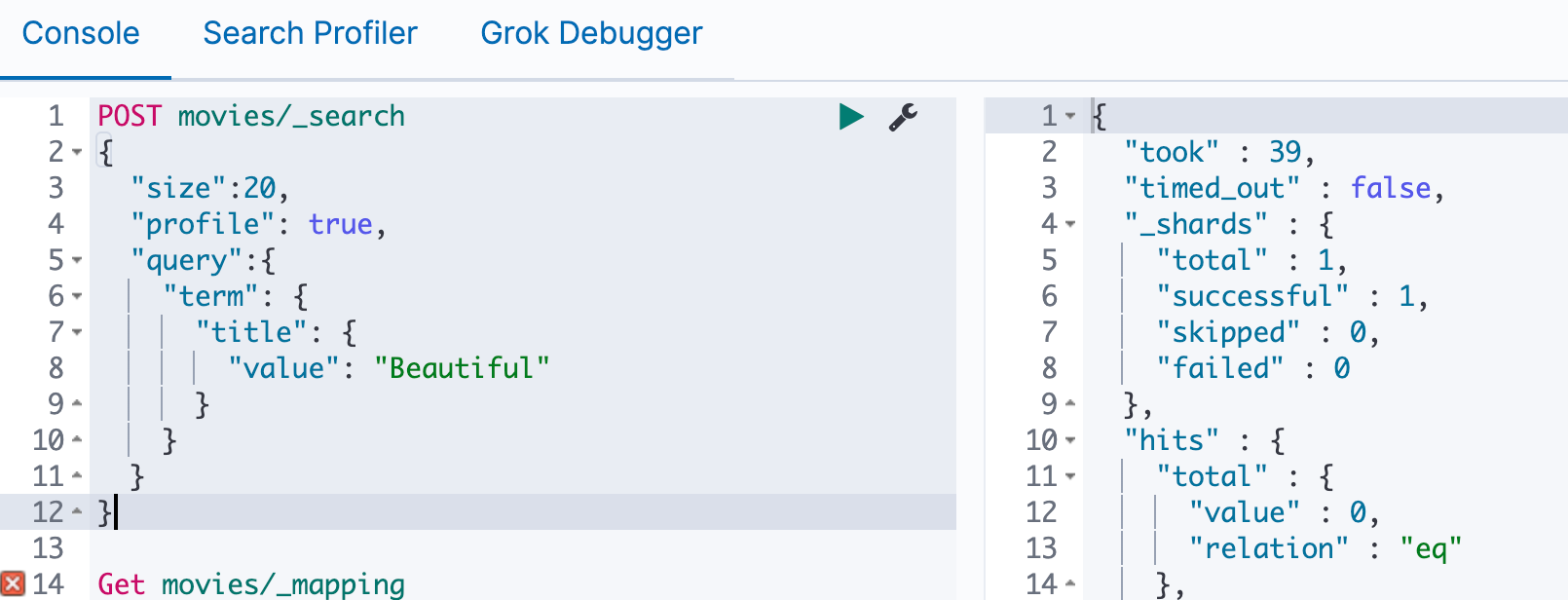
我们改成小写就能查到了
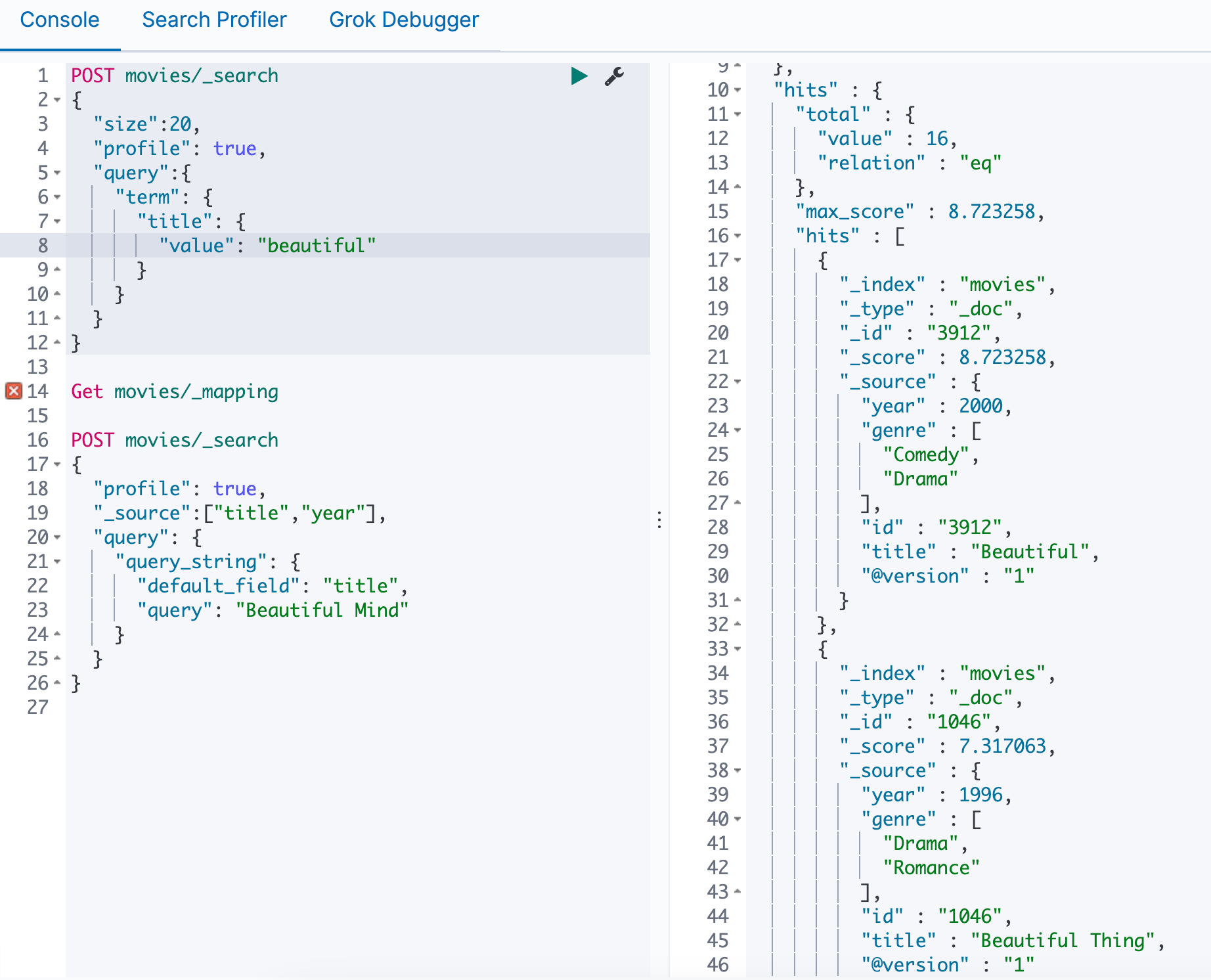
我们可以使用多字段类型,因为keyword没有做任何处理,所以必须完全一致才能查询到
2.2Full text queries全文查询
- 索引和搜索时都会进行分词,查询字符串先传递到一个合适的分词器,然后生成一个供查询的词项列表
- 查询时候,先会对输⼊的查询进⾏分词,然后每个词项逐个进⾏底层的查询,最终将结果进⾏合并。并为每个⽂档⽣成⼀个算分。- 例如查 “Matrix reloaded”,会查到包括 Matrix 或者 reload的所有结果。
API列表
高级全文查询通常用于在全文字段(如电子邮件正文)上运行全文查询。它们了解正在查询的字段是如何分析的,并在执行之前将每个字段的分析器(或 search_analyzer)应用于查询字符串。
此组中的查询包括:
commonterms query:常见术语查询,一种更专业的查询,对不常见的单词给予更多的偏好。intervalsquery:区间查询,一种全文查询,允许对匹配术语的顺序和接近度进行细粒度控制。matchquery:匹配查询,执行全文查询的标准查询,包括模糊匹配和短语或接近度查询。match_phrasequery:匹配短语查询,类似于匹配查询,但用于匹配确切的短语或单词接近度匹配。match_phrase_prefixquery:匹配短语前缀查询,类似于匹配短语查询,但在最后一个单词上进行通配符搜索。multi_matchquery:多匹配查询,匹配查询的多字段版本。query_stringquery:查询字符串查询,支持紧凑的 Lucene 查询字符串语法,允许您在单个查询字符串中指定 AND|OR|NOT 条件和多字段搜索。仅适用于专家用户。simple_query_stringquery:简单查询字符串查询,一种更简单、更健壮的查询字符串语法版本,适合直接暴露给用户。
match query APi说明
返回与提供的文本、数字、日期或布尔值匹配的文档。在匹配之前,会对提供的文本进行分析。匹配查询是执行全文搜索的标准查询,包括模糊匹配的选项。
1 | GET /_search |
query查询:
(必需)您希望在提供的 <字段> 中找到的文本、数字、布尔值或日期。匹配查询在执行搜索之前会分析提供的任何文本。这意味着匹配查询可以在文本字段中搜索已分析的标记,而不是精确的术语。
analyzer分析器:
(可选,字符串)用于将查询值中的文本转换为标记的分析器。默认为为 <字段> 映射的索引时分析器。如果未映射分析器,则使用索引的默认分析器。
auto_generate_synonyms_phrase_query自动生成同义词短语查询:
(可选,布尔值)如果为 true,则会为多词同义词自动创建匹配短语查询。默认为 true。
请参阅使用同义词与匹配查询的示例。
fuzziness模糊度:
(可选,字符串)允许匹配的最大编辑距离。请参阅模糊度以获取有效值和更多信息。请参阅匹配查询中的模糊度示例。
max_expansions最大扩展数:
(可选,整数)查询将扩展到的最大术语数。默认为 50。
prefix_length前缀长度:
(可选,整数)在模糊匹配中保持不变的开头字符数。默认为 0。
fuzzy_transpositions模糊换位:
(可选,布尔值)如果为 true,则模糊匹配的编辑包括两个相邻字符的换位(ab → ba)。默认为 true。
fuzzy_rewrite模糊重写:
(可选,字符串)用于重写查询的方法。请参阅 rewrite 参数以获取有效值和更多信息。
如果模糊度参数不为 0,则匹配查询默认使用 top_terms_blended_freqs_${max_expansions} 的重写方法。
lenient宽松:
(可选,布尔值)如果为 true,则会忽略基于格式的错误,例如为数字字段提供文本查询值。默认为 false。
operator操作符:
(可选,字符串)用于解释查询值中的文本的布尔逻辑。有效值为:
OR(默认)
例如,查询值 “capital of Hungary” 被解释为 “capital OR of OR Hungary”。
AND
例如,查询值 “capital of Hungary” 被解释为 “capital AND of AND Hungary”。
minimum_should_match最小应匹配数:
(可选,字符串)文档必须匹配的最小子句数,以返回该文档。请参阅最小应匹配数参数以获取有效值和更多信息。
zero_terms_query零项查询:
(可选,字符串)指示如果分析器删除所有标记(例如使用停用词过滤器时)是否不返回任何文档。有效值为:
none(默认)
如果分析器删除所有标记,则不返回任何文档。
all
返回所有文档,类似于 match_all 查询。
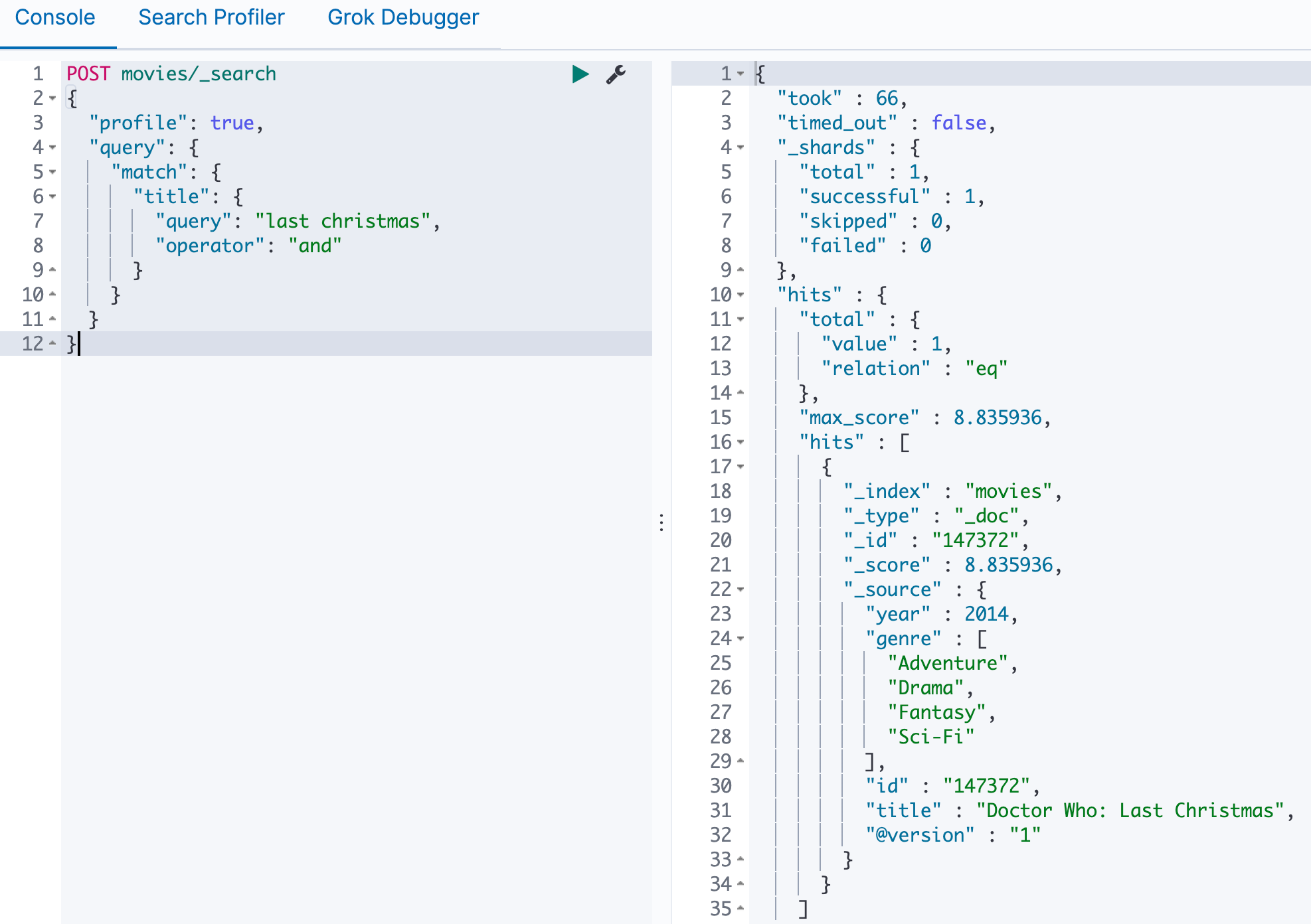
实战
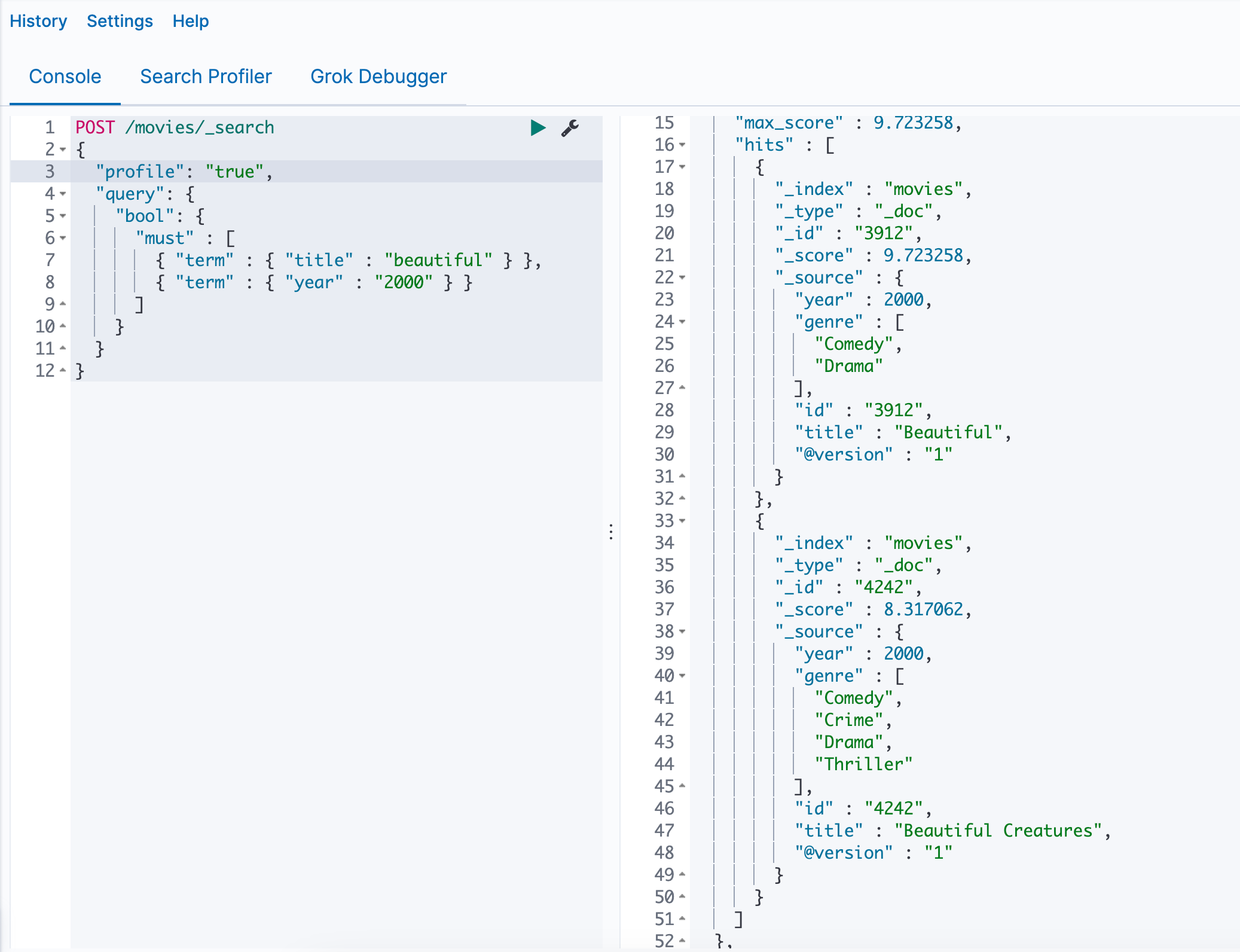
title包含last和christmas
2.3Compound queries复合查询
复合查询包裹其他复合或叶查询,要么是为了组合它们的结果和得分,要么是为了改变它们的行为,或者是从查询切换到过滤上下文。
API列表
这个组中的查询有:
boolquery:布尔查询,用于组合多个叶或复合查询子句的默认查询,如 must、should、must_not 或 filter 子句。must 和 should 子句的得分会被组合 —— 匹配的子句越多越好 —— 而 must_not 和 filter 子句则在过滤上下文中执行。boostingquery:提升查询,返回匹配positive查询的文档,降低匹配negative查询的文档的得分。constant_scorequery:常量得分查询,一个包裹另一个查询的查询,但在过滤上下文中执行它。所有匹配的文档都被赋予相同的 “常量” 得分。dis_maxquery:析取最大查询,一个接受多个查询的查询,并返回匹配任何查询子句的文档。布尔查询组合所有匹配查询的得分,而析取最大查询使用单个最佳匹配查询子句的得分。function_scorequery:函数得分查询,通过函数修改主查询返回的得分,以考虑诸如流行度、近期性、距离或使用脚本实现的自定义算法等因素。
constant score query API说明
包裹一个过滤查询,并返回每一个匹配的文档,其相关性得分等于提升参数值。
将 Query 转成 Filter,忽略 TF-IDF 计算,避免相关性算分的开销
Filter 可以有效利⽤缓存
1 | GET /_search |
filter过滤器
(必需,查询对象)你希望运行的过滤查询,有term、range、terms、exists、missing、prefix、wildcard、regexp、bool等。任何返回的文档都必须匹配此查询。
过滤查询不计算相关性得分。为了提高性能,Elasticsearch 会自动缓存经常使用的过滤查询。
boost提升
(可选,浮点数)用于每个匹配过滤查询的文档的常量相关性得分的浮点数。默认值为 1.0。
boolean query API说明
支持针对多个字段进行搜索!!!
一种匹配与其他查询的布尔组合相匹配的文档的查询。布尔查询映射到 Lucene 的 BooleanQuery。它使用一个或多个布尔子句构建,每个子句具有类型化的出现。出现类型如下:
must必须:该查询内容必须出现在匹配的文档中,并将对得分有所贡献。
filter过滤器:该查询内容必须出现在匹配的文档中。然而,与must不同的是,查询的得分将被忽略。过滤器子句在过滤器上下文中执行,这意味着忽略得分并且子句被考虑用于缓存。
should应该:该查询内容应该出现在匹配的文档中。
must_not必须不:该查询内容不得出现在匹配的文档中。子句在过滤器上下文中执行,这意味着忽略得分并且子句被考虑用于缓存。由于忽略得分,将为所有文档返回 0 分。
布尔查询采用 “更多匹配更好” 的方法,因此每个匹配的must或should子句的得分将相加,以提供每个文档的最终_score。
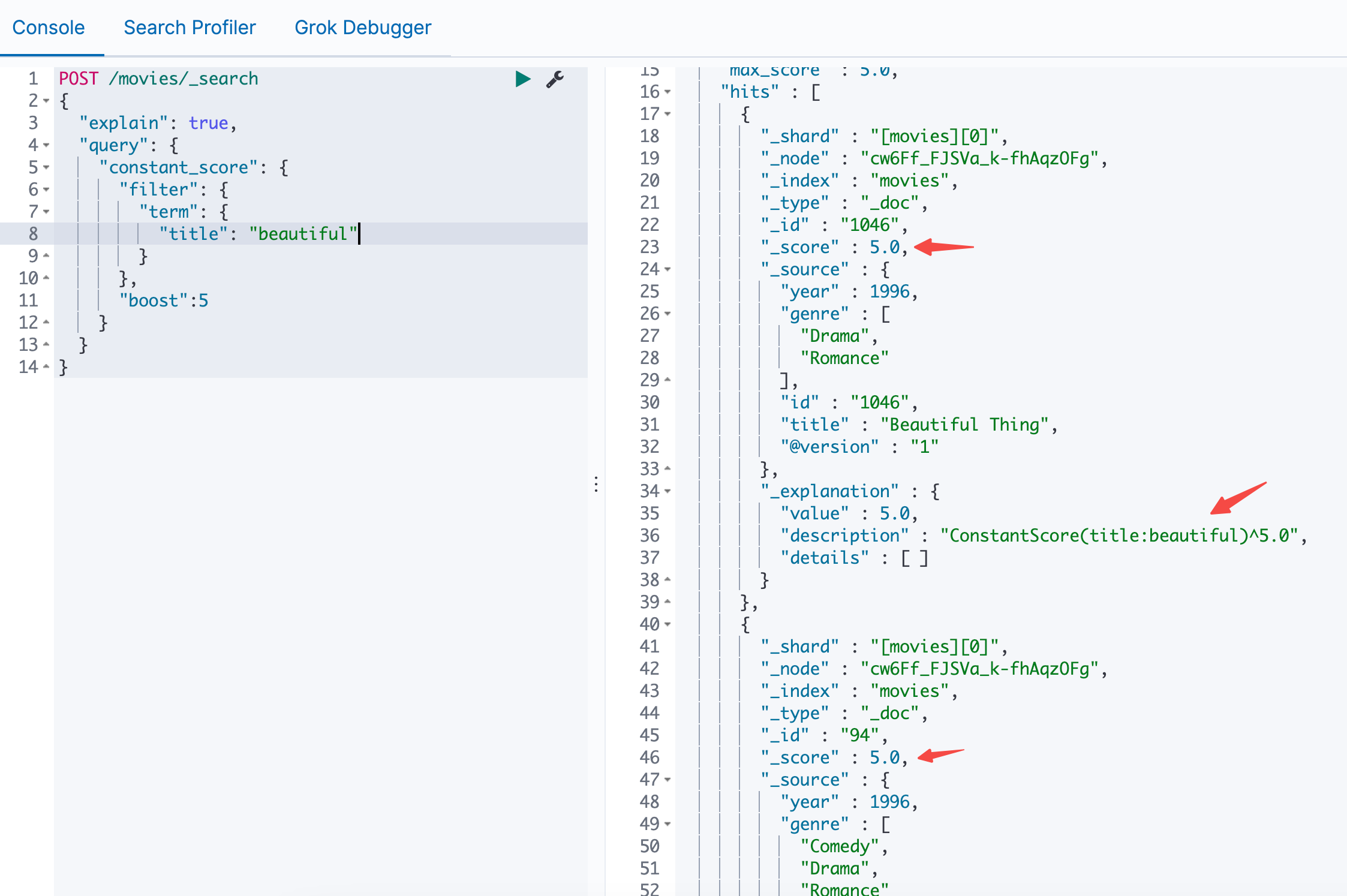
1 | POST _search |
实战
所有值都是5
使用bool查询多个字段
三、搜索的相关性算分
前面将Search API的时候,总提到score,这是怎么计算的?
3.1相关性 – Relevance
- 搜索的相关性算分,描述了⼀个⽂档和查询语句匹配的程度。ES 会对每个匹配查询条件的结果进⾏算分 _score
- 打分的本质是排序,需要把最符合⽤户需求的⽂档排在前⾯。ES 5 之前,默认的相关性算分采⽤ TF-IDF,现在采⽤ BM 25
3.2TF-IDF
词频 TF
- Term Frequency:检索词在⼀篇⽂档中出现的频率,计算词频的公式一般为TF = 词在文档中出现的次数 / 文档的总词数。
- 例如,有一篇文档内容为 “这是一个关于 Elasticsearch 的示例文档,Elasticsearch 是一个非常强大的搜索引擎。”,其中 “Elasticsearch” 这个词出现了 2 次,文档总词数约为 30 个(具体词数可根据实际情况统计),那么 “Elasticsearch” 的词频 TF = 2 / 30 ≈ 0.067。
- 度量⼀条查询和结果⽂档相关性的简单⽅法:简单将搜索中每⼀个 词的 TF 进⾏相加
- Stop Word:如 “的” 在⽂档中出现了很多次,但是对贡献相关度⼏乎没有⽤处,不应该考虑他们的 TF
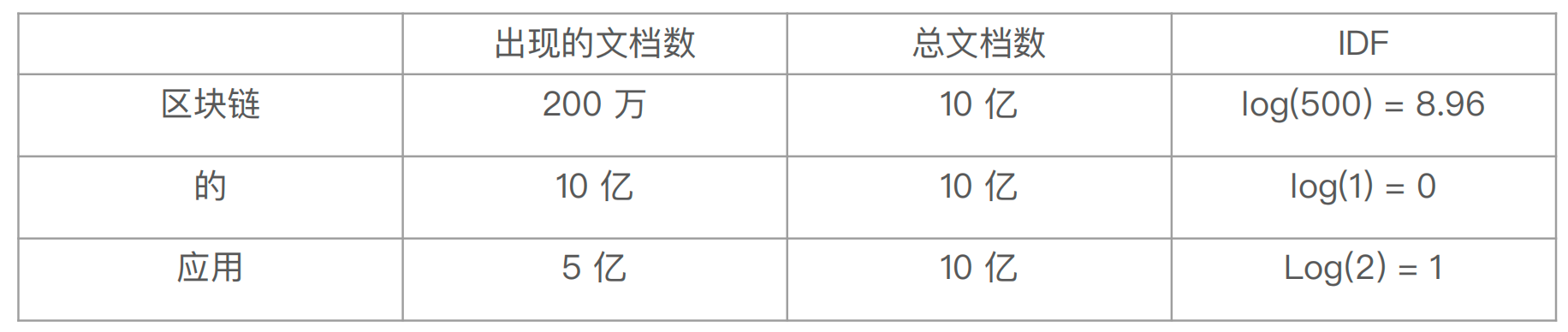
逆⽂档频率 IDF
- DF:检索词在所有⽂档中出现的频率
- IDF(Inverse Document Frequency )简单说 = log(全部⽂档数/检索词出现过的⽂档总数)
以query为“区块链的应用”为例,计算的IDF值为:
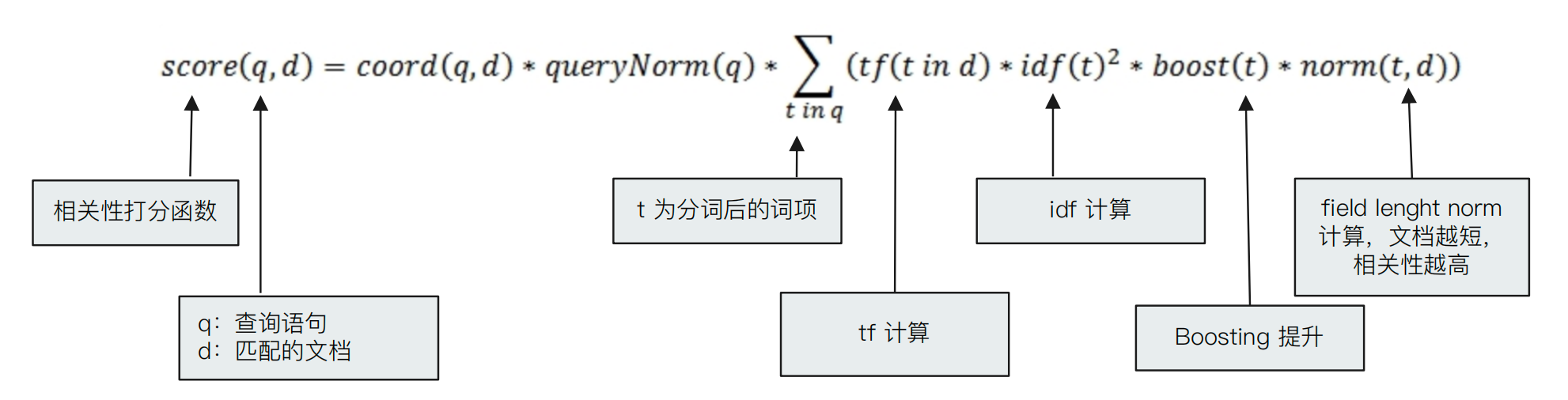
TF-IDF
TF-IDF 本质上就是将 TF 求和变成了加权求和:TF(区块链)*IDF(区块链) + TF(的)*IDF(的)+ TF(应⽤)*IDF(应⽤)
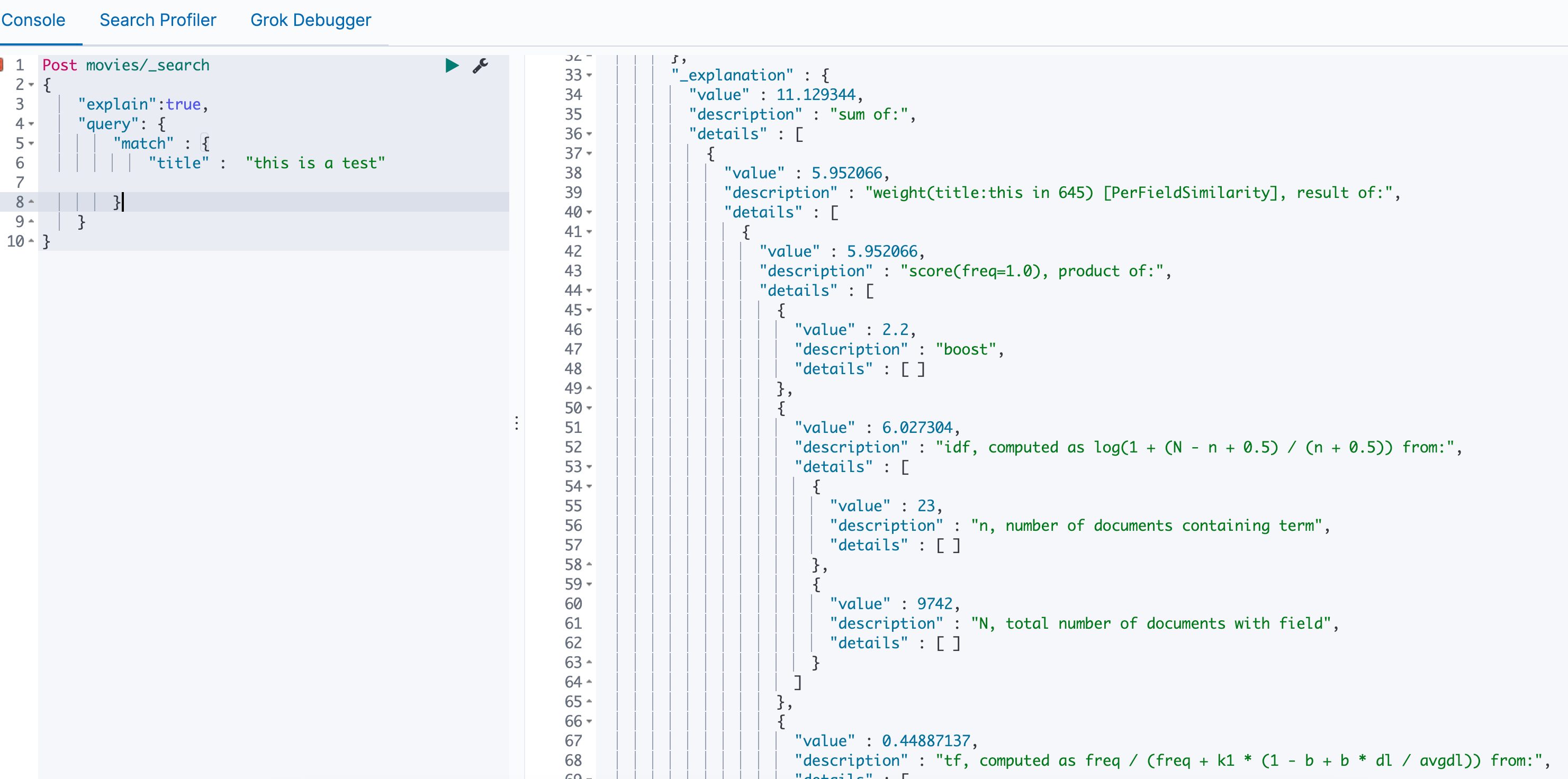
3.3 explain
我们可以使用explain查看计算过程
四、排序
Elasticsearch 默认采⽤相关性算分对结果进⾏降序排序,我们可以通过设定 sorting 参数,⾃⾏设定排序,此时_score 为 null。
1 | Post movies/_search |
4.1执行过程
当客户端向 ES 发送一个带有排序要求的查询请求时,例如按某个数值字段 “price” 进行升序排序,请求会被发送到集群中的一个节点,这个节点作为协调节点(coordinating node)来处理整个请求。
- 协调节点处理请求
- 解析请求:协调节点首先解析查询请求,确定要查询的索引、查询条件以及排序字段等信息。
- 分发请求:协调节点将查询请求分发给索引所在的各个分片(shard)。这些分片可能分布在不同的节点上。
- 分片执行查询与排序
- 查询数据:每个分片接收到请求后,首先根据倒排索引找到符合查询条件的文档集合。例如,查询条件是 “category: electronics”,分片会利用倒排索引快速定位到所有类别为 “electronics” 的文档。
- 读取正排索引:对于每个符合查询条件的文档,分片从对应的正排索引(Doc Values)中读取排序字段的值。例如,对于上述找到的电子产品文档,从 “price” 字段的 Doc Values 中读取每个文档的价格。
- 本地排序:分片在本地内存中对读取到的文档按照排序字段的值进行排序。如果排序字段是 “price” 且要求升序排序,分片会将价格低的文档排在前面。排序算法通常采用快速排序或归并排序等高效算法。
- 协调节点合并结果
- 收集分片结果:各个分片完成本地查询和排序后,将排序后的部分结果返回给协调节点。每个分片返回的结果数量通常由
from和size参数决定。例如,如果from = 0,size = 10,每个分片会返回自己排序后的前 10 个文档。 - 全局排序:协调节点接收到所有分片返回的结果后,将这些结果进行合并,并再次进行排序,以确保最终返回给客户端的结果是全局排序后的结果。例如,假设有 3 个分片,每个分片返回了 10 个文档,协调节点会将这 30 个文档合并,并重新按照 “price” 字段进行排序,然后根据
from和size参数截取最终要返回给客户端的文档子集。
- 返回结果
协调节点将最终排序后的结果返回给客户端。
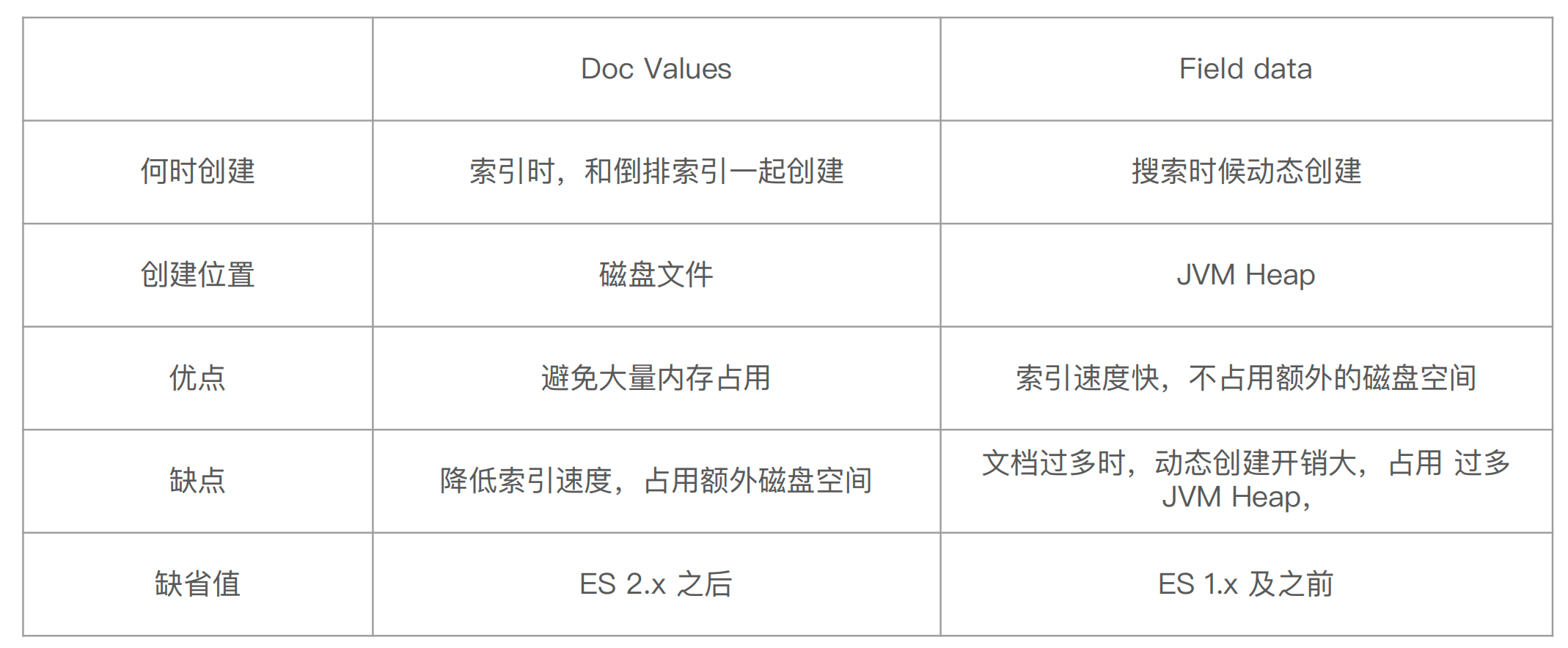
4.2正排索引
Doc Values 是列式存储,对 Text 类型⽆效
五、深度分页
默认情况下,查询按照相关度算分排序,返回前10 条记录,可以通过from、size控制开始位置和期望获得的文档数。
1 | Post movies/_search |
5.1出现原因
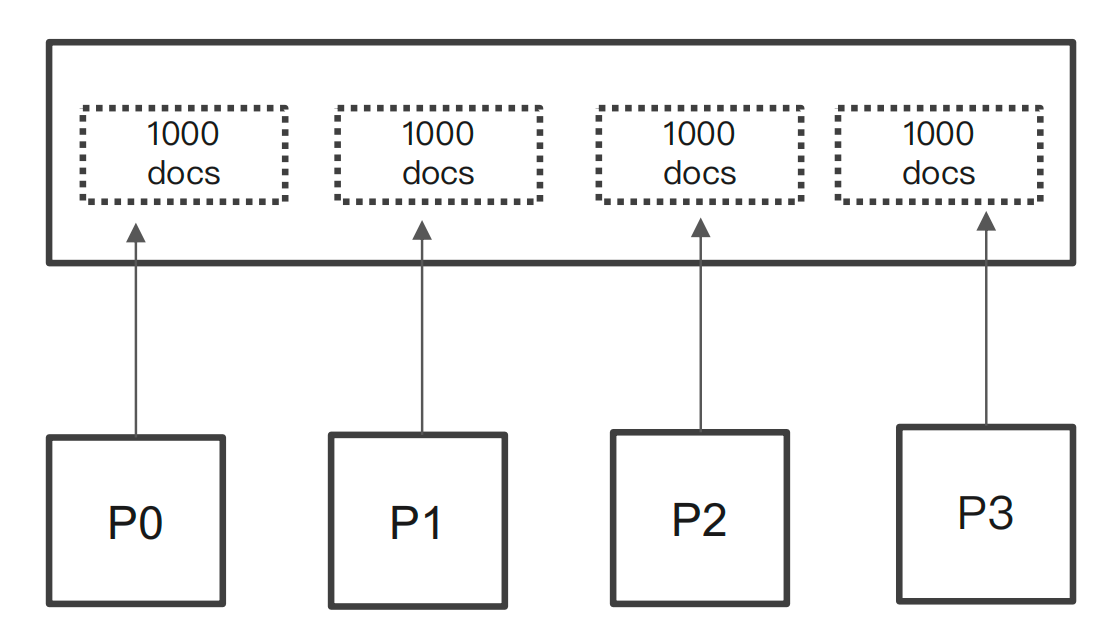
ES 天⽣就是分布式的。查询信息,但是数据分别保存在多个分⽚,多台机器上。
当⼀个查询: From = 990, Size =10
- 会在每个分⽚上先都获取 1000 个⽂档。然后,通过 Coordinating Node 聚合所有结果。最后再通过排序选取前 1000 个⽂档
- ⻚数越深,占⽤内存越多。为了避免深度分⻚带来的内存开销。ES 有⼀个设定,默认限定到10000 个⽂档
5.2解决方案
我们可以通过Search After 避免深度分⻚的问题,可以实时获取下⼀⻚⽂档信息,但有两个缺点
不⽀持指定⻚数(From)
只能往下翻
原因
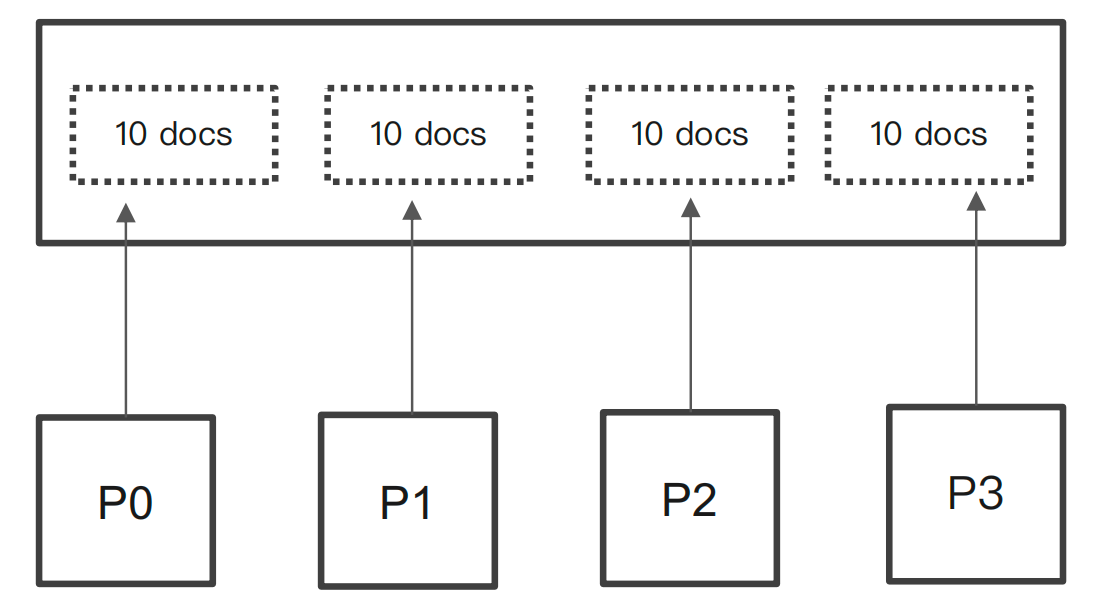
执行过程为
- 第⼀步搜索需要指定 sort,并且保证值是唯⼀的(可以通过加⼊ _id 保证唯⼀性)
- 然后使⽤上⼀次,最后⼀个⽂档的 sort 值进⾏查询
为什么能解决深度分页问题?假定 Size 是 10,当我们查询到 990 – 1000时,因为已经知道上次的最后一个值了,只需要通过唯⼀排序值定位,在每个分片上获取该值之后的10个文档即可,这样将每次要处理的⽂档数都控制在 10。
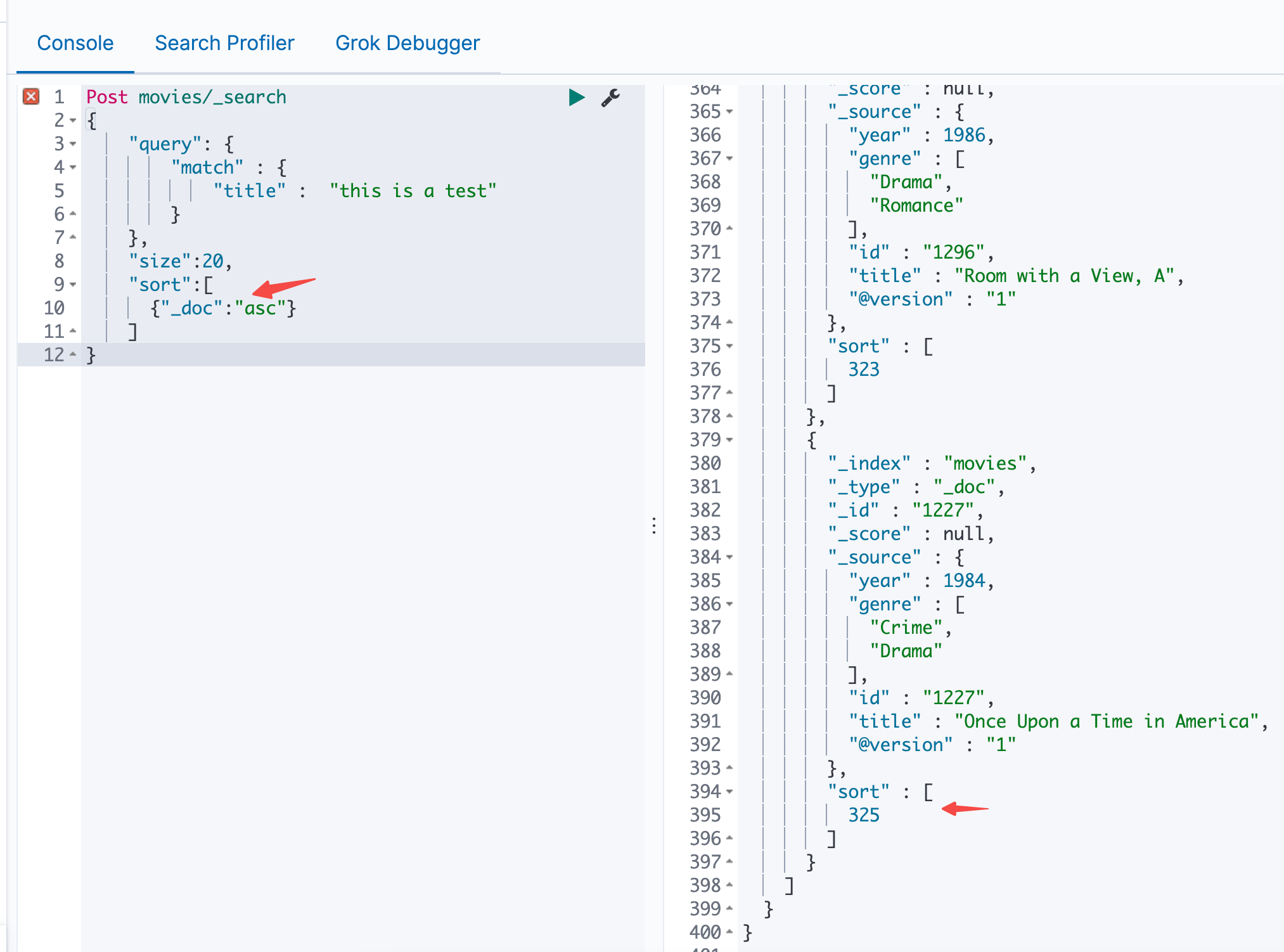
实战
使用sort,并获取最后的值
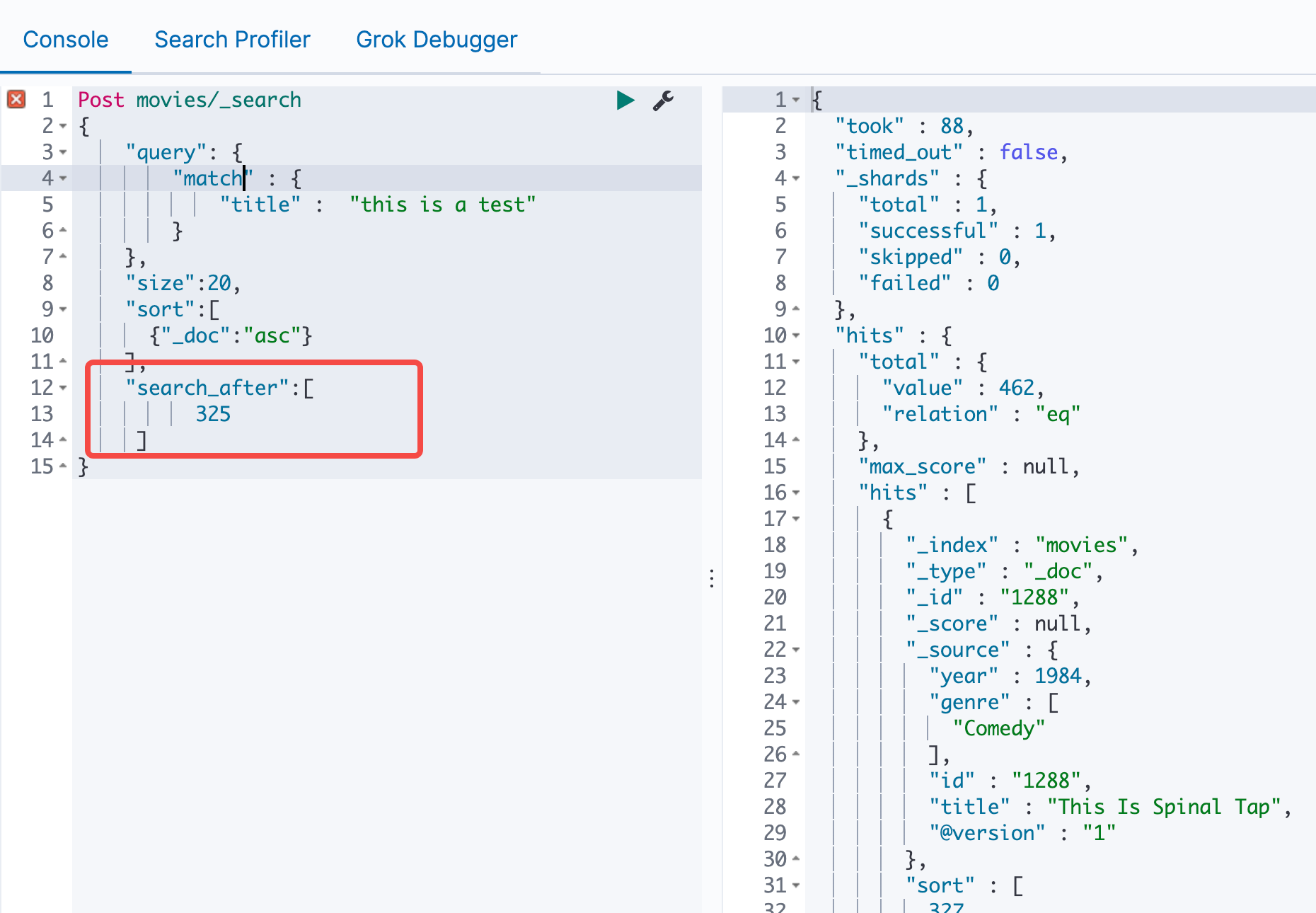
使用search_after
总结
怎么比较好的学习ES?
我觉得首先要学一下概况或者说框架,这个可以使用极客时间的《Elasticsearch 核心技术与实战》。
然后看ES的官方文档,各种细节都在里面,而且内容准确无误,坏处是没有英文的。
最后动手实践,demo实践,生产实践,慢慢就能更加的了解了。