上一次聊了5 Elasticsearch深入搜索,这次来看看聚合。API链接为: https://www.elastic.co/guide/en/elasticsearch/reference/7.1/query-dsl-nested-query.html 。
聚合说明
什么是聚合?Kibana上的这些图就是聚合,底层通过ES能够实现。
ES支持哪些聚合?聚合有很多类型,主要看Metrics和Bucket
- Bucket Aggregation:一些列满足特定条件的文档的集合
- Metric Aggregation:一些数学运算,可以对文档字段进行统计分析
- Pipeline Aggreagtion:对其它的聚合结果进行二次聚合
- Matrix Aggregation:支持对多个字段的操作并提供一个结果矩阵
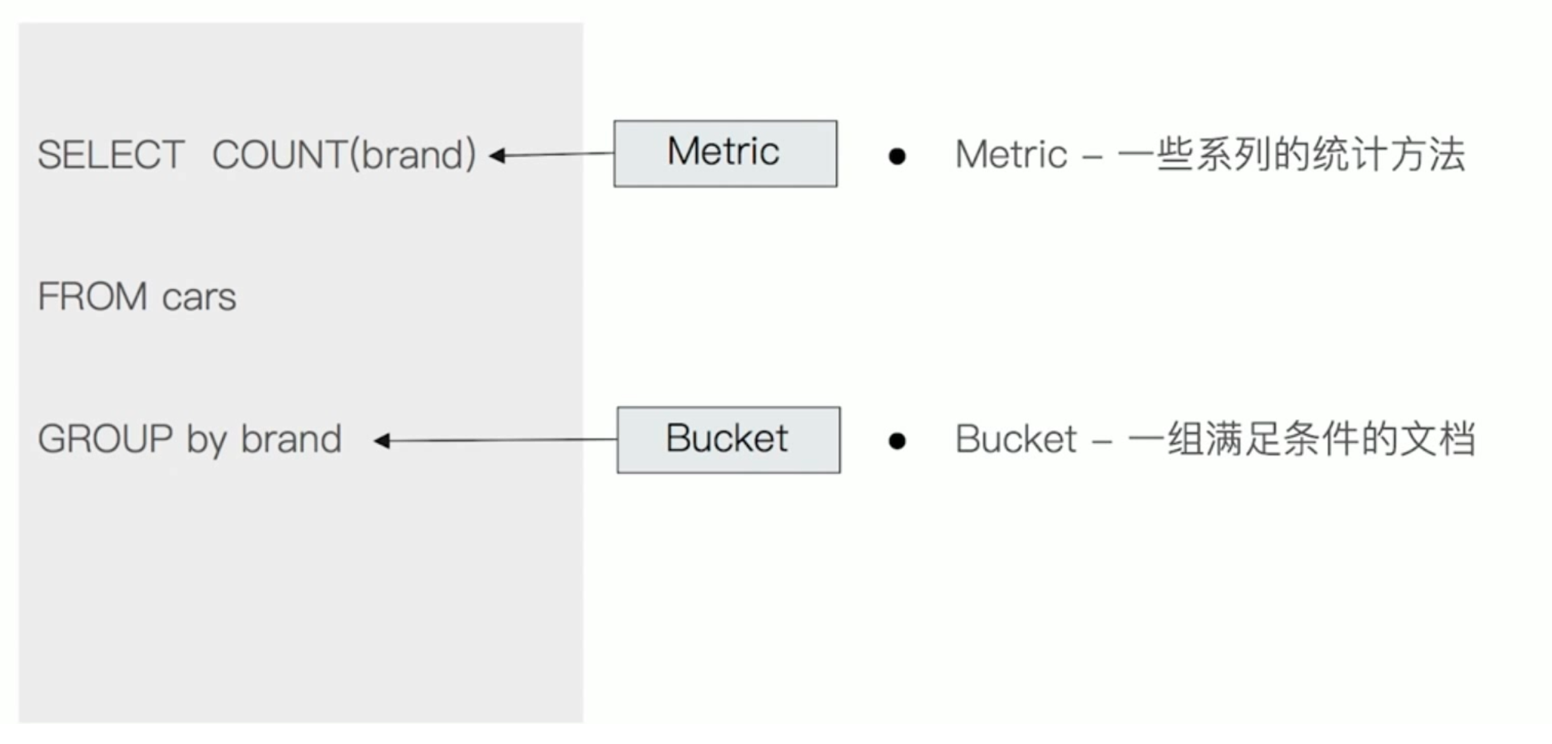
Bucket和Metric如果用MySQL类比
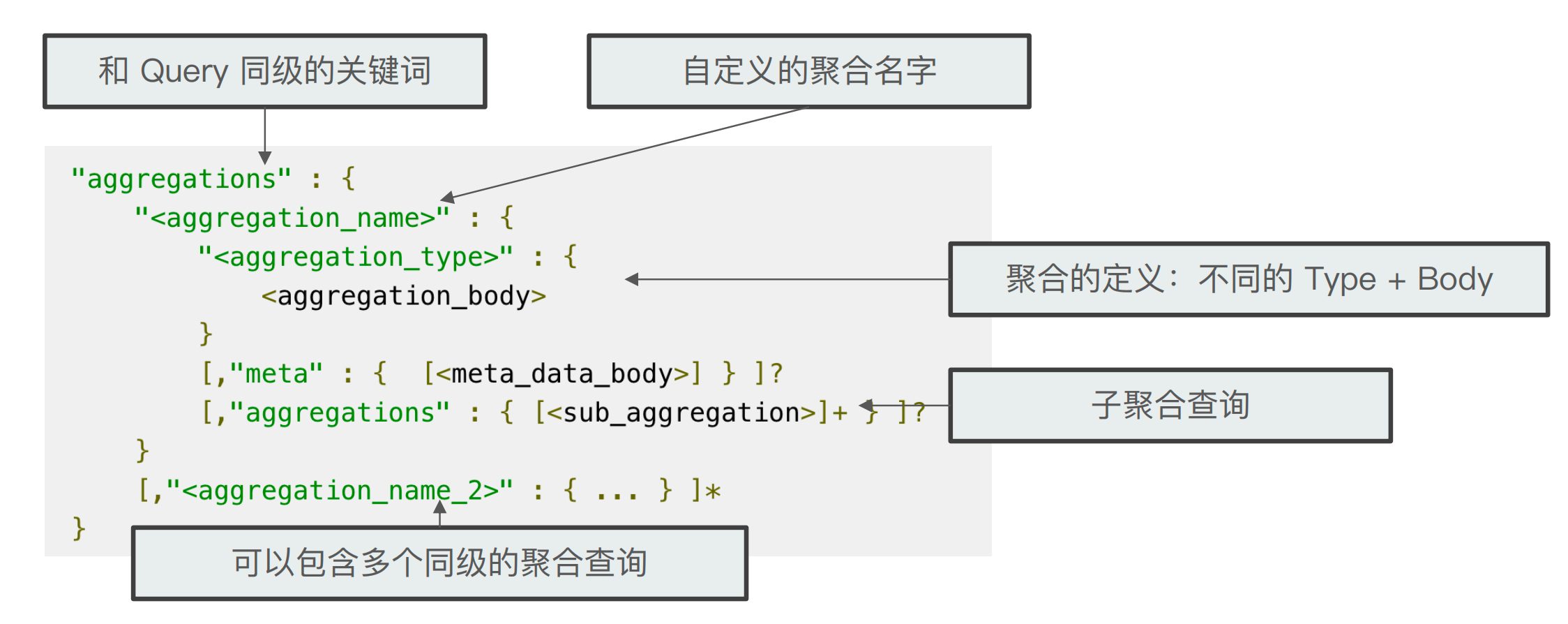
聚合API
Aggregation属于Search的一部分,语法如下
Metric
说明
- Metric会基于数据集计算结果,除了支持在字段上进行计算,同时也支持在脚本(painless script)产生的结果之上进行计算
- 大多数Metric是数学计算,仅输出一个值,如min/max/sum/avg/cardinality
- 部分metric支持输出多个数值,如stats/percentiles/percentile_ranks
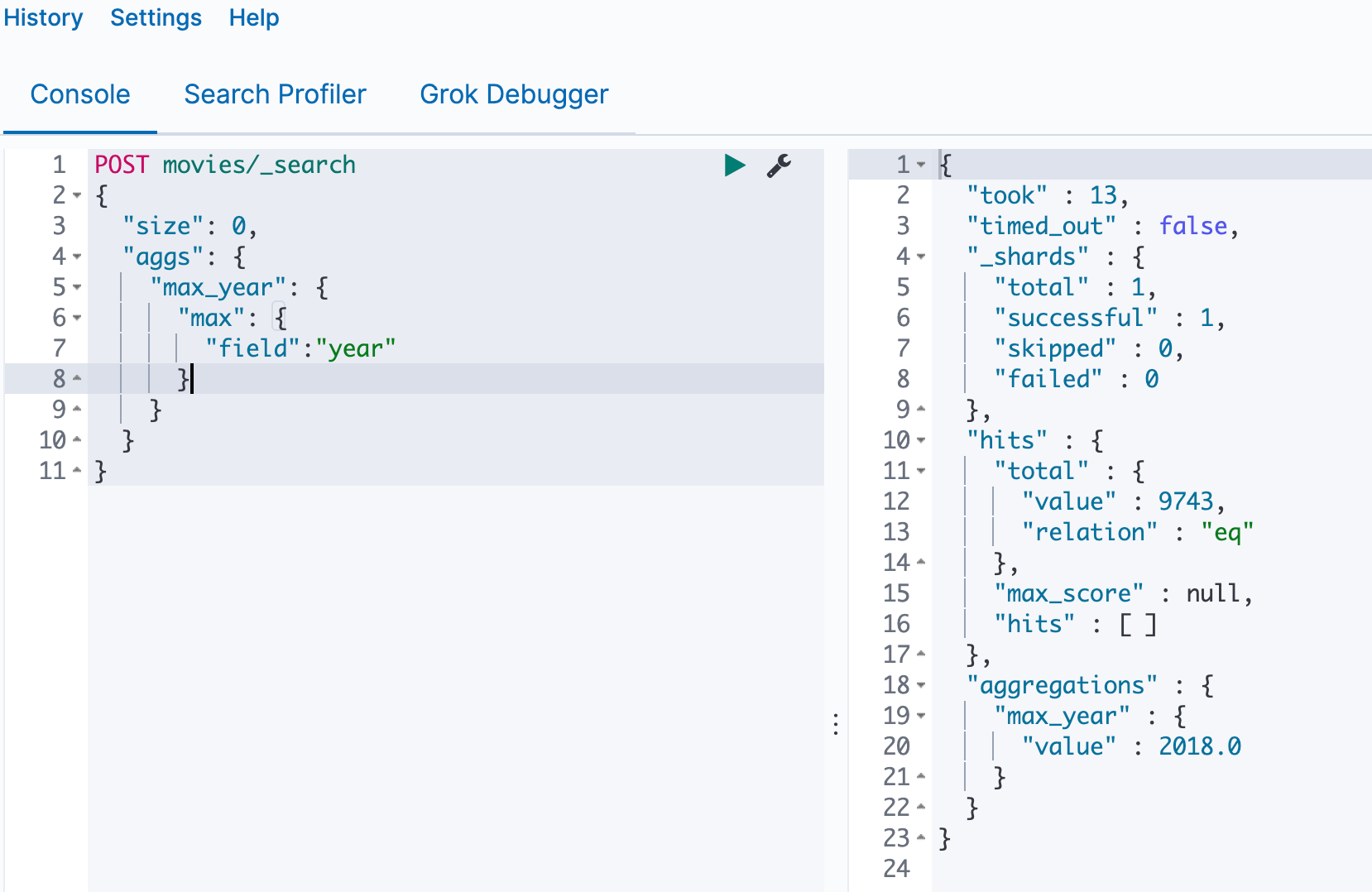
实战
查询电影中,最大的一年
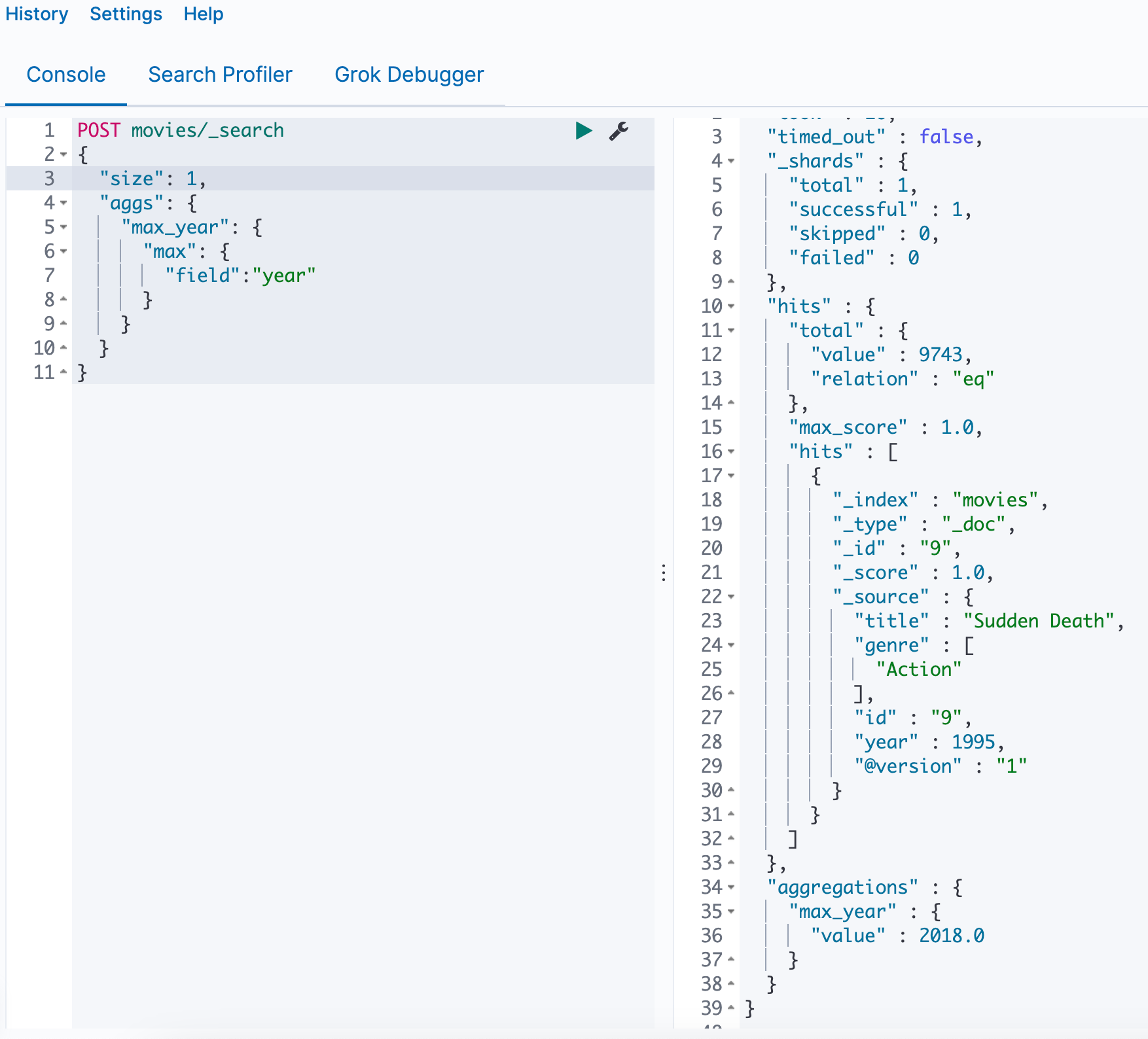
如果size大于1,会返回对应的条目信息
Bucket
说明
- 按照⼀定的规则,将⽂档分配到不同的桶中,从⽽达到分类的⽬的。类似于MySQL的group。
- ⽀持嵌套:也就在桶⾥再做分桶。⼦聚合分析可以是Bucket和Metric
- Term Aggregations对于text字段,需要打开fielddata才可以使用

实战
按照年group
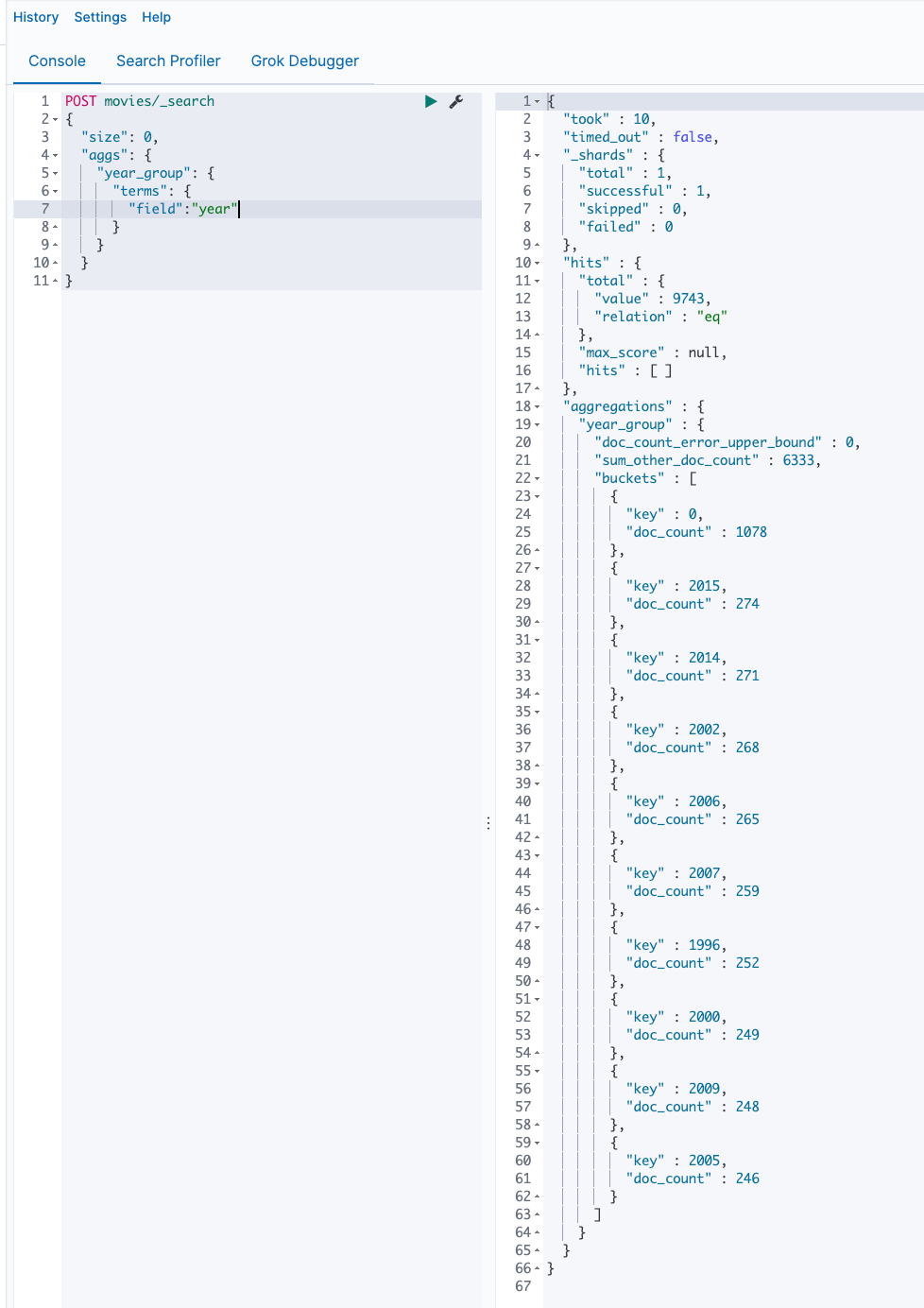
设置返回数量
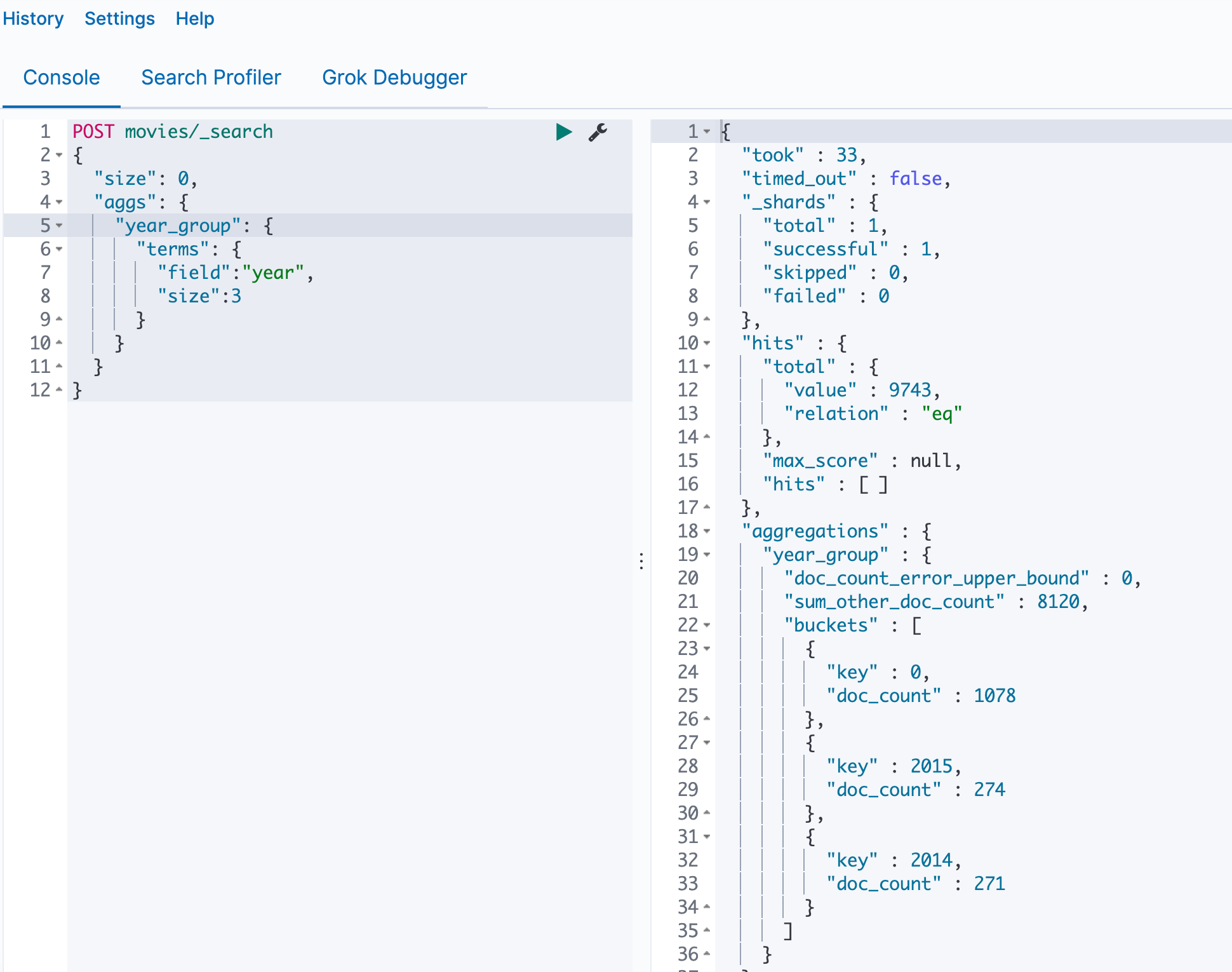
先按年group,然后按年内的类型group
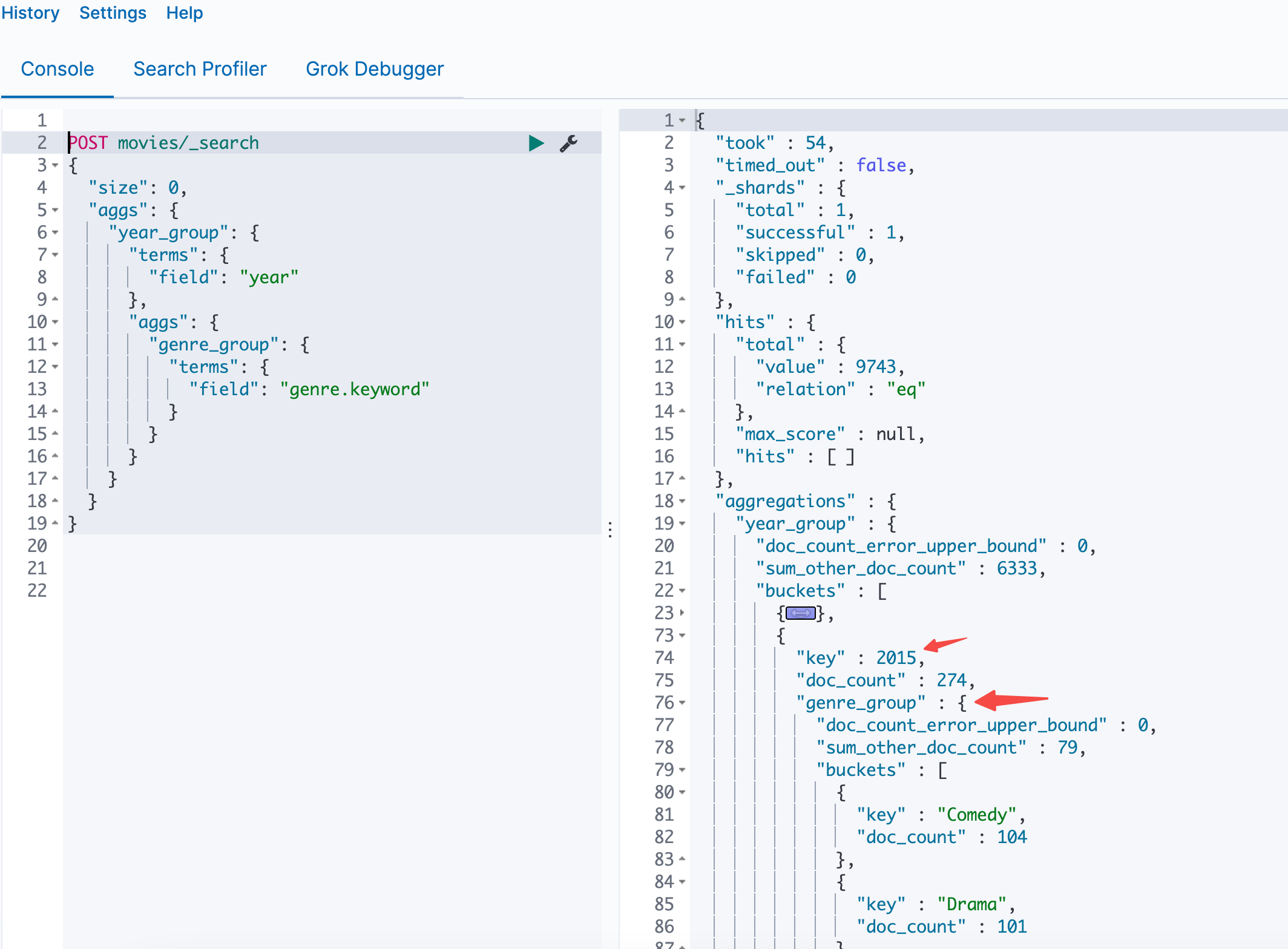
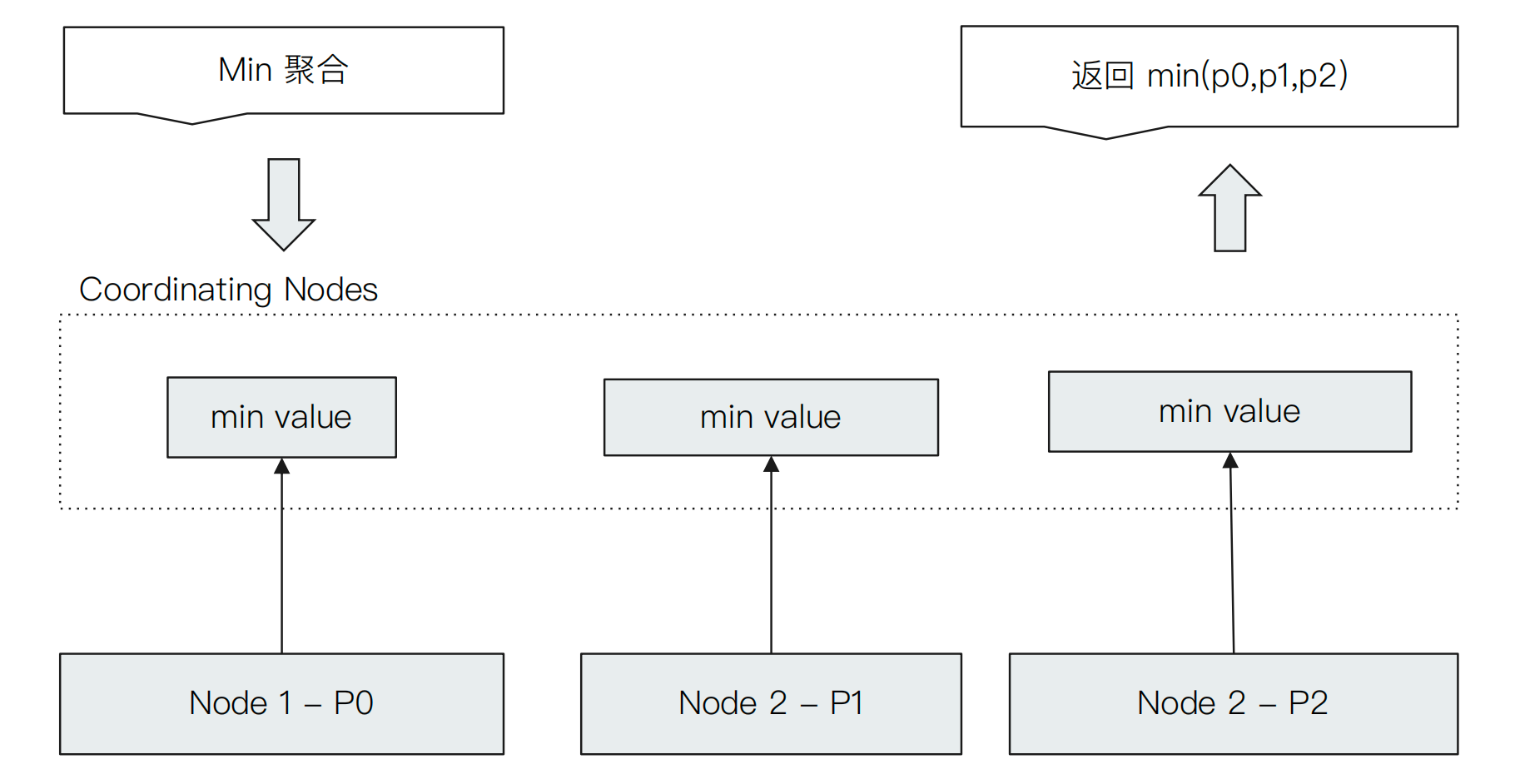
聚合执行过程
聚合其实是从各个分片获取数据,然后进行组合的过程,Min和Term的聚合过程如下
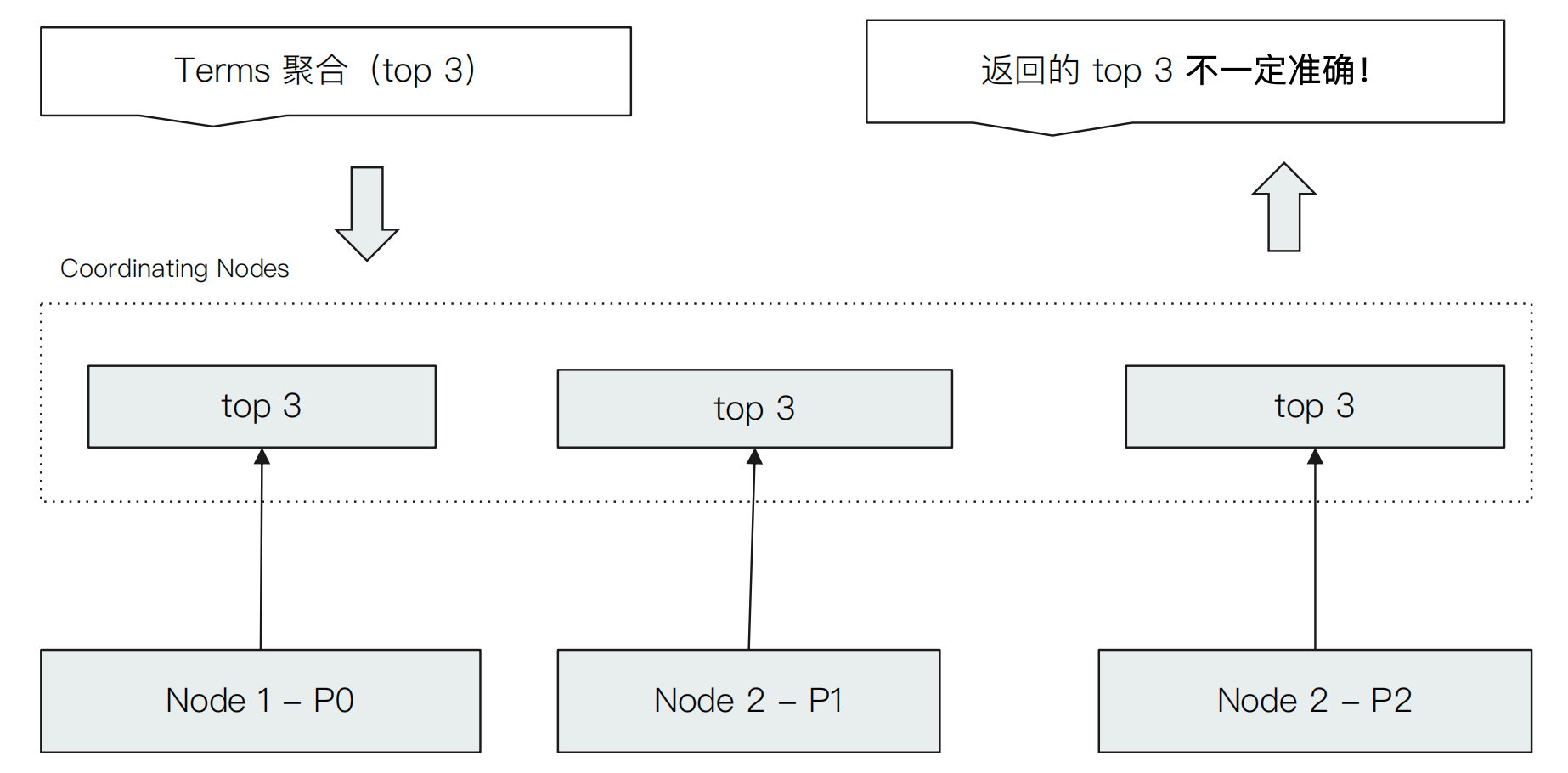
通过Terms的样例,能够发现聚合的结果未必是准确的,因为数据是分散的,每个Node的top3未必是全局的top3。ES提供了一些参数可以用来解决或者优化这个问题。
关联查询
Joining queries为”关联查询” 或 “连接查询”。这种查询方式主要用于在 Elasticsearch 中处理具有层次结构的数据,例如,一个博客文章(父文档)和它的评论(子文档)。通过使用has_child、has_parent、parent_id等查询类型,可以实现对这类数据的有效检索。
Nested(嵌套)场景
“nested”(嵌套)是一种数据类型和查询方式,用于处理复杂的数据结构。具体来说,它允许你在文档中存储数组类型的对象,并且这些对象中的每个元素都可以被单独索引和查询。
假设写了一个电影的mapping
1 | PUT my_movies |
写入一条电影doc
1 | POST my_movies/_doc/1 |
进行查询
1 | POST my_movies/_search |
发现竟然能够查到结果:
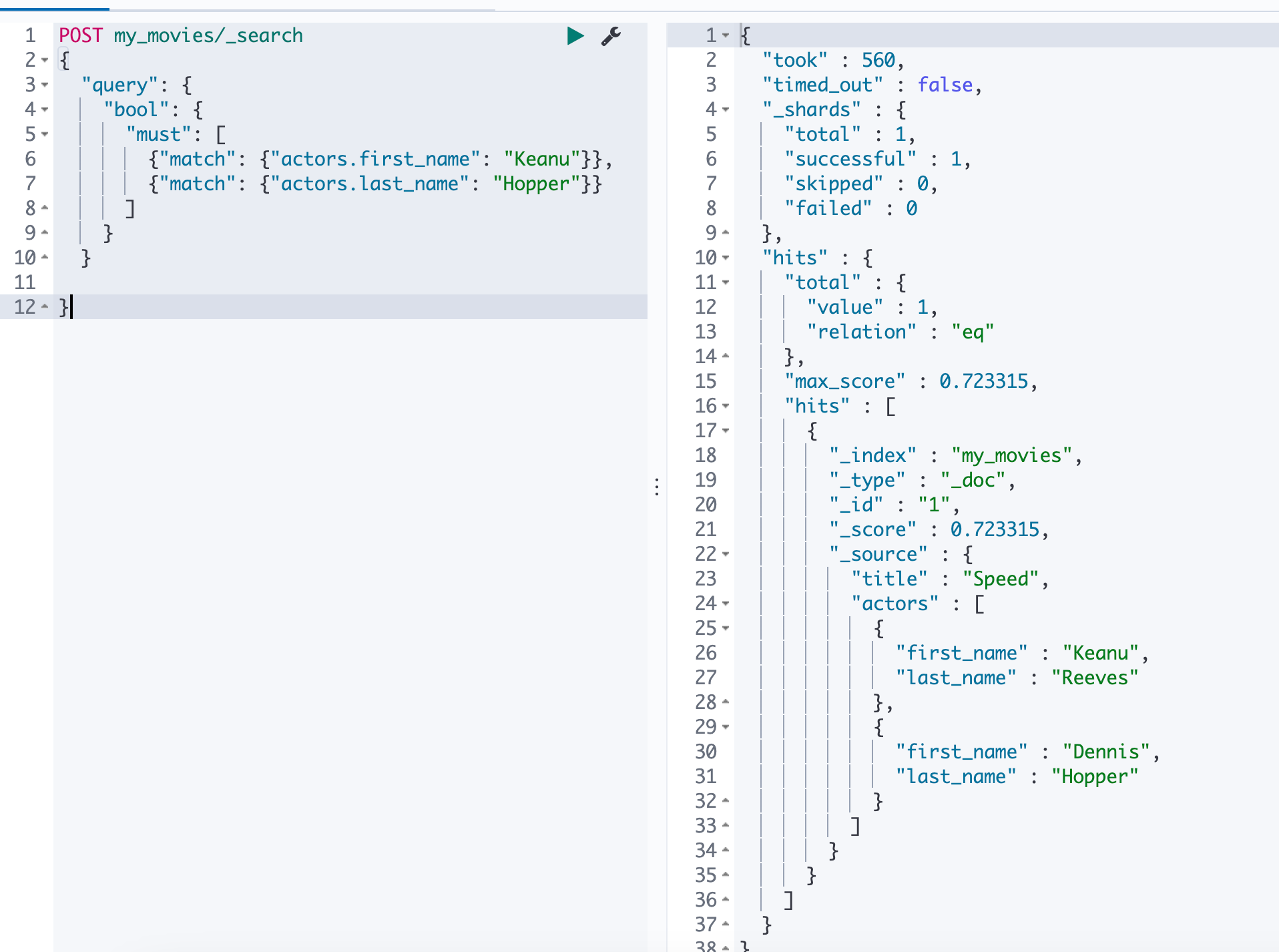
这是因为ES存储时,内部对象的边界并没有考虑在内,JSON 格式被处理成扁平式键值对的结构

为了解决这个问题,我们使用Nested。创建 Nested 对象 Mapping,即增加type为nested
1 | PUT my_movies |
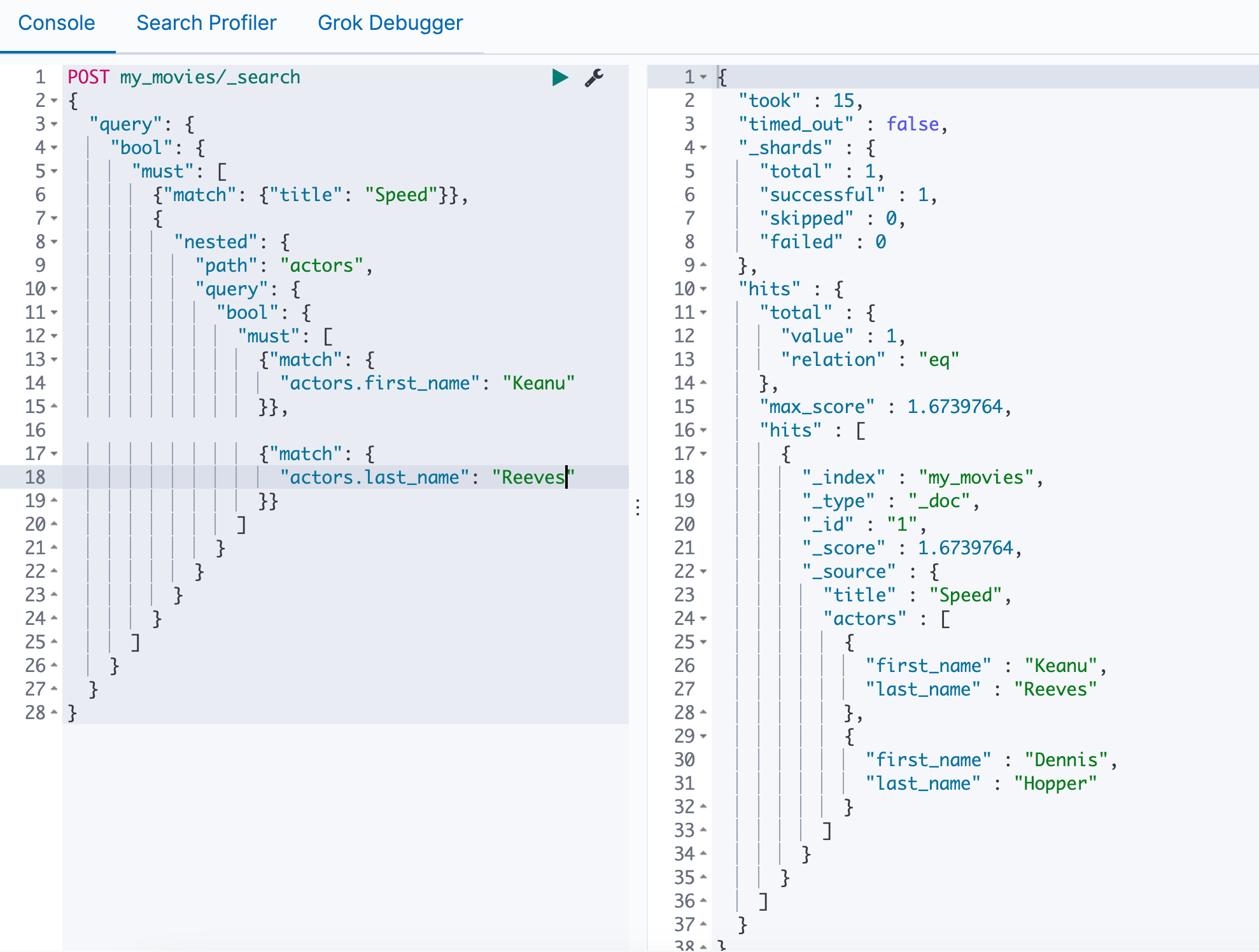
重新插入数据,使用nested进行查询发现查不到了,如果使用正确的first_name和last_name可以查到
1 | POST my_movies/_search |
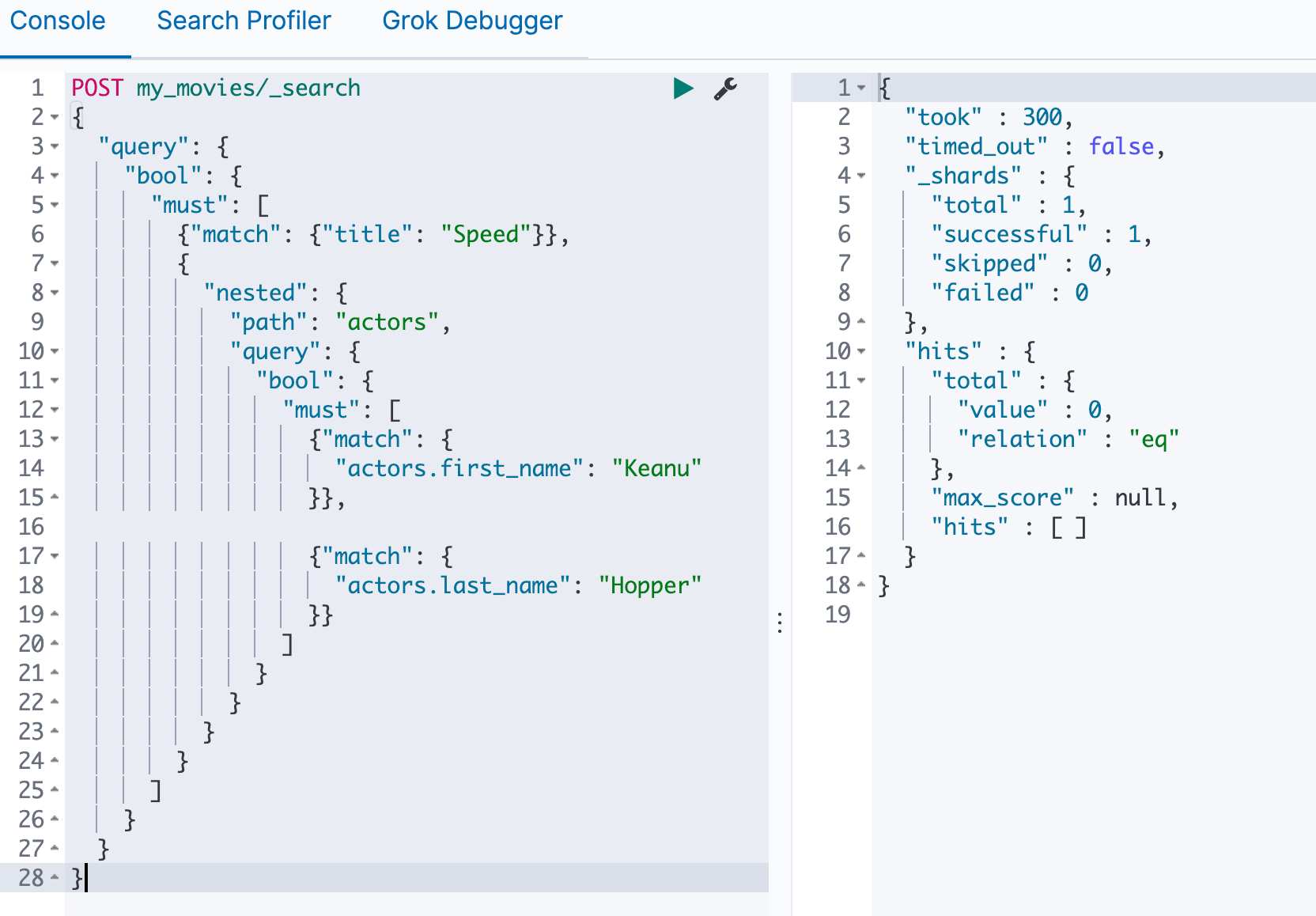
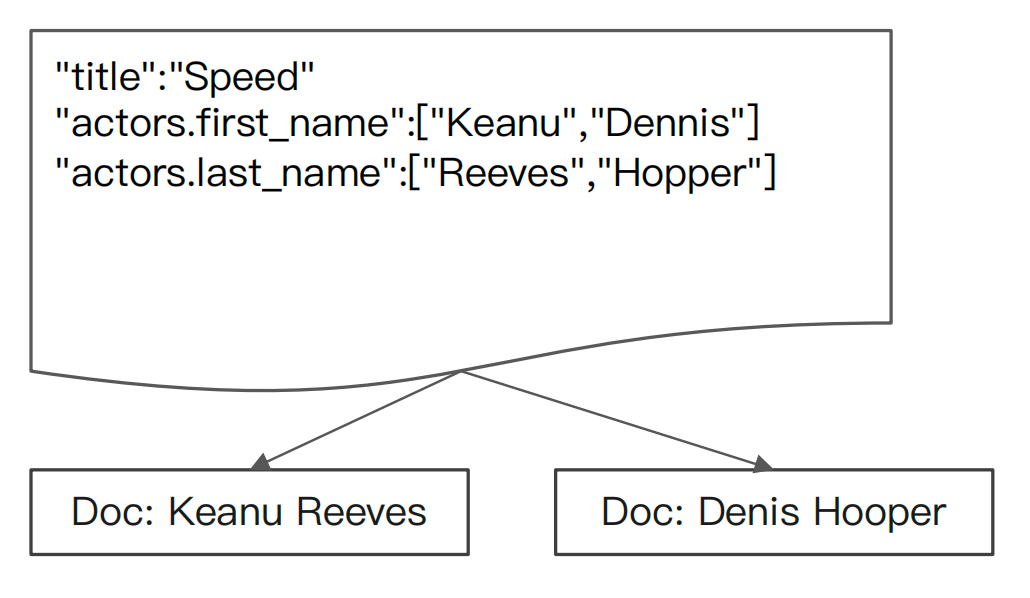
这是因为在ES内部, Nested ⽂档会被保存在两个 Lucene⽂档中,会在查询时做 Join 处理
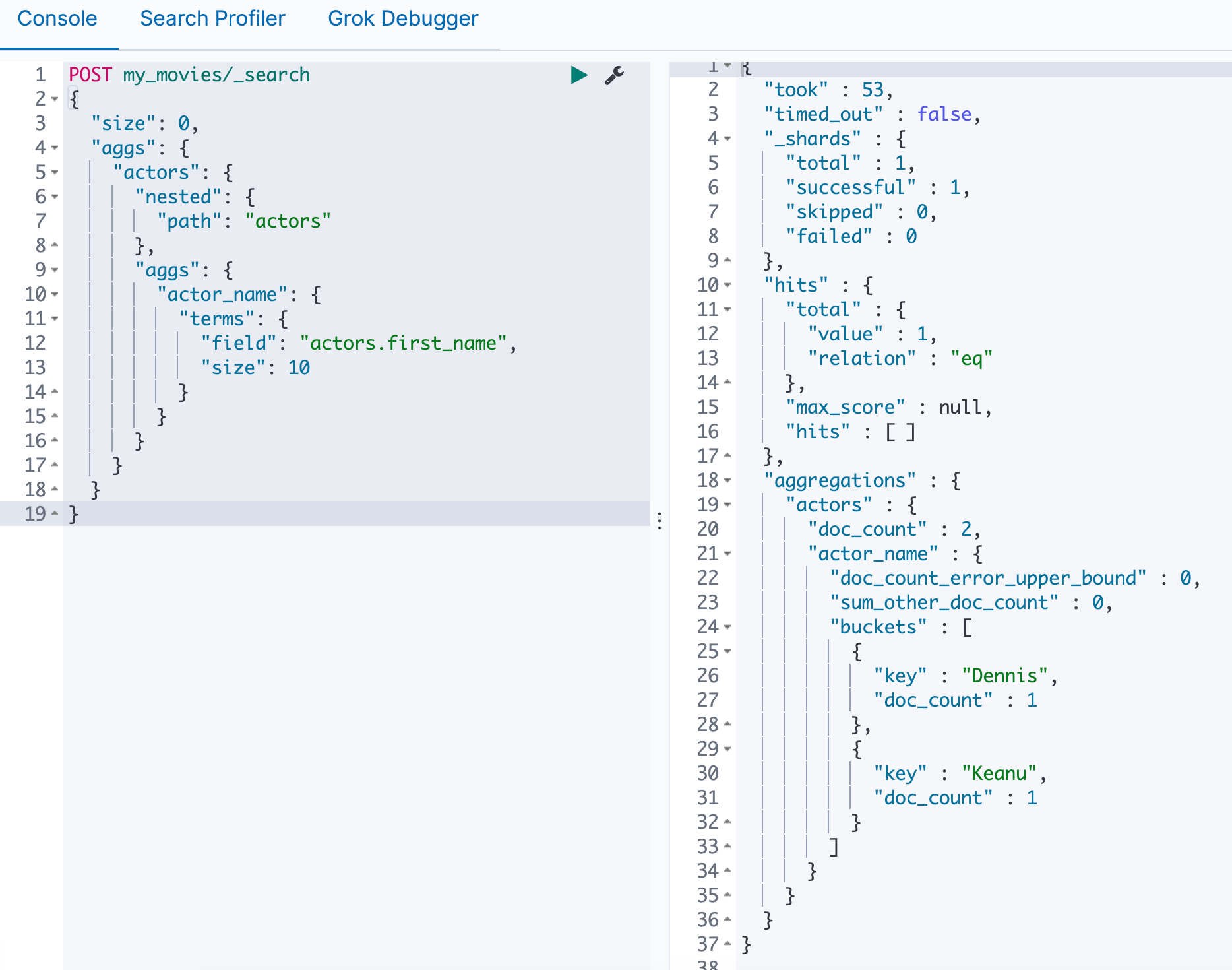
Nested(嵌套)聚合
我们可以在Nested上做聚合
1 | POST my_movies/_search |